高并发内存池--C++项目实践
项目介绍
简介
这是一款高并发的C++内存管理项目,原型是google的一个开源项目tcmalloc,全称Thread_Caching Malloc,即线程缓存的malloc,tcmalloc实现了高效的多线程内存管理,可以用于替代系统的内存分配的相关的函数malloc,new,free,delete等
实际上原型项目内容很多,但本着渐进学习的理念,我们可以先把tcmalloc最核心的框架简化,模拟实现出一个自己的高并发内存池。在掌握了其中的精华的设计思想和编程技巧后,我们可以再进一步实现或改造原本的tcmalloc项目,或者将学习成果用于其它项目或者更多用途
应用背景
tcmalloc是一项十分常用的技术,很多对性能要求较高的场景都能用到它
- 高性能服务器
TCMalloc被广泛应用于高并发的服务器程序中,如Web服务器和数据库服务器。这些场景下,需要快速分配和释放内存,TCMalloc通过线程缓存机制减少了锁的竞争,提升了性能。
- 游戏开发
- 游戏引擎通常需要频繁分配和释放内存,尤其是在运行时动态创建和销毁对象。
TCMalloc的低延迟和高吞吐量使其成为游戏开发的理想选择。
- 游戏引擎通常需要频繁分配和释放内存,尤其是在运行时动态创建和销毁对象。
- 大数据处理
- 在处理大数据时,内存管理效率至关重要。许多大数据框架(如
TensorFlow和Apache Beam)采用TCMalloc作为内存分配器,以提高性能和降低内存碎片。
- 在处理大数据时,内存管理效率至关重要。许多大数据框架(如
- 机器学习和深度学习
- 在训练和推理过程中,机器学习和深度学习模型通常需要频繁地进行内存分配。
TCMallocs能够有效管理这些内存请求,提升模型的训练和推理效率。
- 在训练和推理过程中,机器学习和深度学习模型通常需要频繁地进行内存分配。
- 微服务架构
- 在微服务架构中,服务之间的请求通常会涉及大量的内存分配。使用
TCMalloc可以减少内存分配的延迟,提高服务的响应速度。
- 在微服务架构中,服务之间的请求通常会涉及大量的内存分配。使用
- 高性能计算(HPC)
在高性能计算环境中,内存分配的效率直接影响计算性能。TCMalloc的设计使其能够在这种环境中表现出色,提供更快的内存管理。 - C++ 应用程序
TCMalloc 是 C++ 应用程序中常用的内存分配器之一,特别是在需要处理大量小对象的情况下。它可以替代默认的malloc和free函数,提高内存分配的效率。 - 实时系统
在实时系统中,内存分配的确定性和性能至关重要。TCMalloc提供了较低的延迟和稳定的性能,使其适合用于此类应用。
- 总结
- TCMalloc 的高效性能和线程安全特性使其在多线程应用、服务器、游戏、数据处理和高性能计算等领域得到了广泛应用。选择 TCMalloc 作为内存分配器,可以显著提高应用程序的性能和响应能力。
技能应用
在本次项目,您将应用如下技能甚至更多
- C++面向对象设计
- 链表、哈希表等数据结构
- 操作系统内存管理
- 单例模式
- 多线程
- 互斥锁
以及本次项目的核心技术: 池化技术
池化技术介绍

很多情况下,不论资源是否稀缺,以及申请资源的操作是否成功,前往申请资源这一操作本身就消耗了不少性能/其它资源(尤其时间)。此时采用池化技术,一次性申请一大块资源,然后优先使用提前申请好的资源,这样可以就可以提高运行效率,减小不必要的额外开销。
实际上在计算机领域已经有很多应用池化技术的地方了。举例如下图
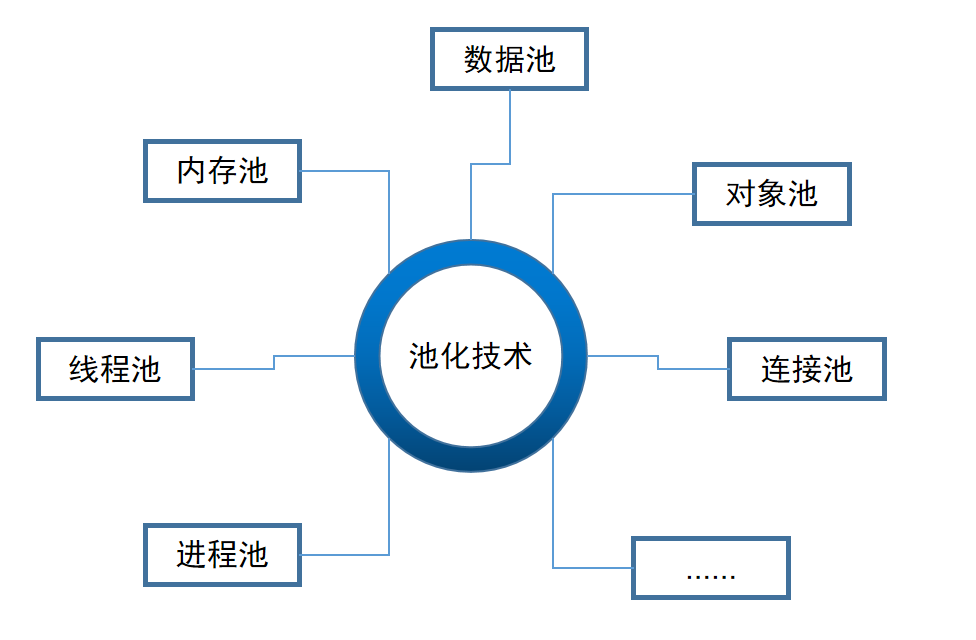
当然,我们要着重实现的就是内存池
内存池介绍
内存池是池化技术在内存管理上的具体应用。程序预先从操作系统申请一块足够大的内存,此后,当程序中需要申请内存时,不需要直接向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存时,并不是真正将内存返回给操作系统,而是返回给内存池。内存池充当了程序和操作系统的内存交互的中间人,由它负责从操作系统申请的内存的管理
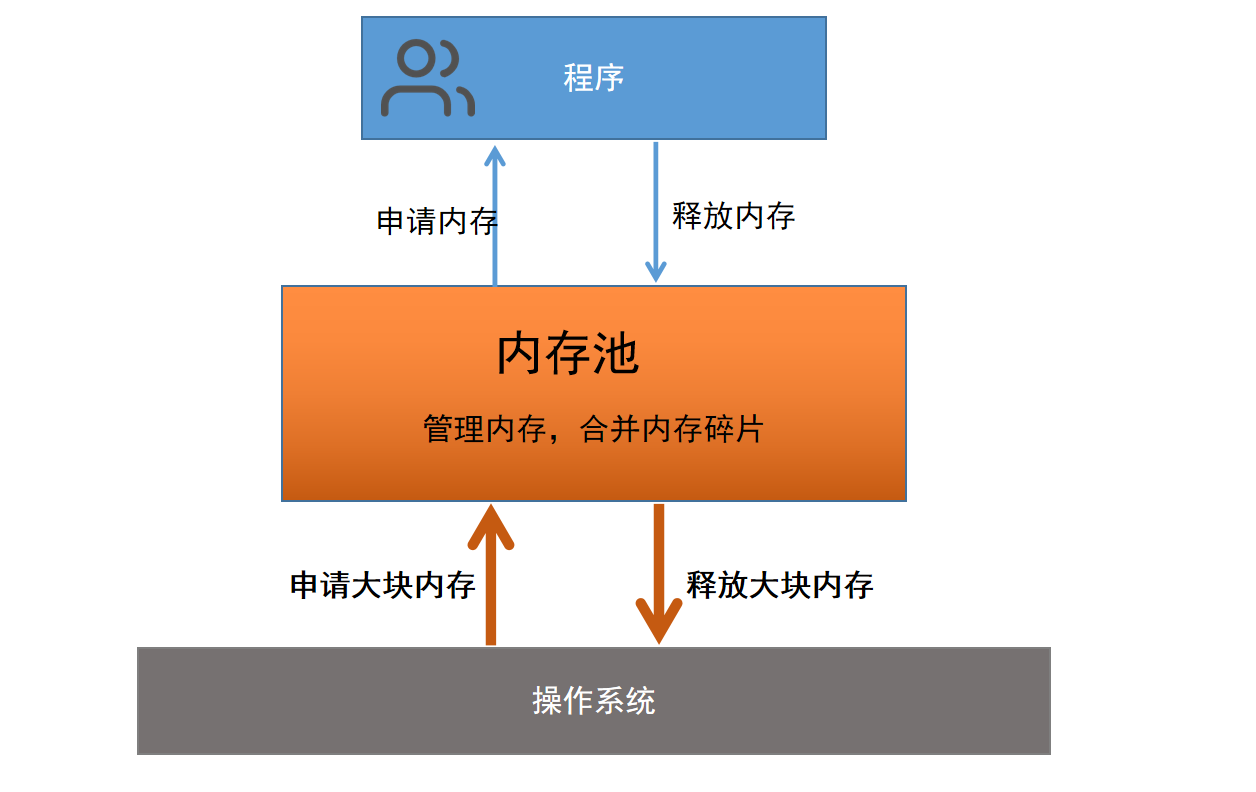
但是实际应用中的内存池还要解决一个问题–内存碎片化。内存碎片又分为外碎片和内碎片。
外碎片是指申请了一些离散的内存后,在未分配的内存中,存在一部分空闲的连续内存区域太小,利用不上,导致合计的内存足够的同时,却不能满足部分内存分配的请求。
内碎片则是由于出于一些对齐的需求,在分配出去的内存中,存在多分配出去的内存无法被利用。关于如何缓解内碎片的问题,我们会在后面的代码部分进行更详细的介绍
项目设计
针对多核多线程运行环境下,申请内存会发生严重锁竞争的问体i,我们的concurrent memory pool主要从以下几个问题出发,设计实际的模块结构
- 内存申请的性能问题
- 多线程环境下锁竞争的问题
- 内存碎片问题
针对性能问题,我们可以用池化技术解决;而锁竞争问题,可以通过给每一个线程一个独享的线程池来避免锁竞争;至于内存碎片问题,则是通过多层内存池解决。

三者的关系如上图:
thread cache:线程缓存是每个线程独享的,用小于256KB的内存分配。线程只从这里申请内存,而由于这部分内存是线程独享的,所以不需要加锁,避免了锁竞争,使线程的内存分配更为高效central cache:中央缓冲则是由所有线程下的线程级内存池thread cache共享,thread cache从central cache中按需获取内存对象。而central cache负责在合适的时机回收thread cache中的对象,避免一个线程占用了太多空闲内存,而其它线程分配内存不足的情况。这样就能达到负载均衡的效果,使内存分配在多个线程中更能按需分配。显然central cache是一种临界资源,所以从central cache获取内存的过程是需要加锁的。但是不一定要整个内存池要加锁,实际上我们这里用的是桶锁,只给所需要用到的指定哈希桶加锁,能减少锁竞争,其次只有thread cache申请的内存不足以消耗时,才会向central cache申请内存,所以时间上的锁竞争机会更少了。page cache:页缓存作为central cache的上级缓存,存储的内存对象是以页为单位的,向下分配也是以页为单位的。当central cache申请内存时,page cache负责分配出一定数量的page,并切割成定长大小的内存块分配给central cache。特别的,当一个span的几个跨度页的对象都回收以后,page cache会回收central cache满足条件的span对象,并合并相邻的页,组成更大的页,缓解内存碎片问题
自由链表+哈希桶设计实现池化技术
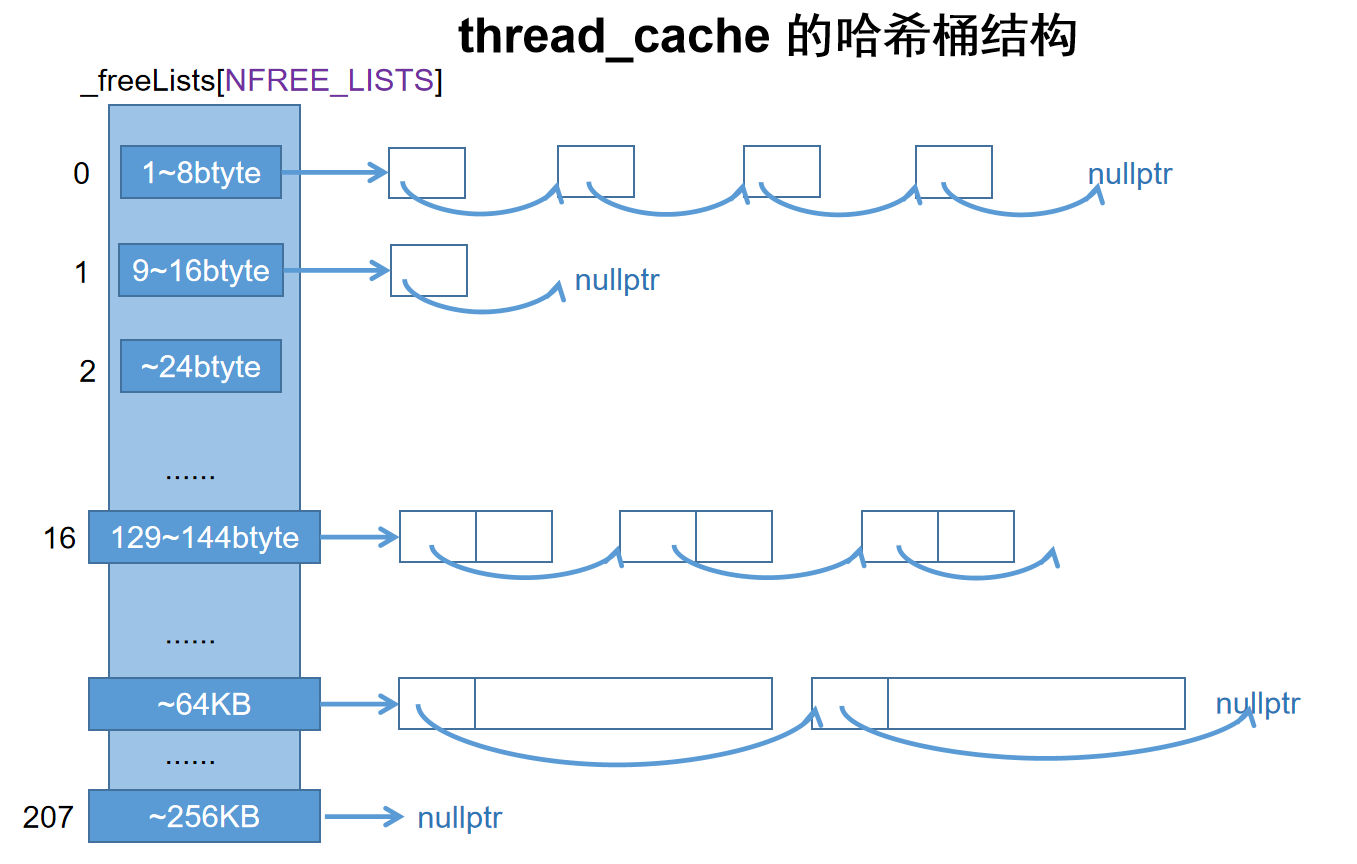
自由链表:因为下层向上层申请的内存往往是离散的而不是连续的,而返回内存时获得的空闲内存,往往也是离散的,所以对于同样大小的空闲内存,我们要用链表数据结构把它们串在同一个链表上,这样可以方便地再次分配内存。那么我们该怎么高效地实现链表呢?相比额外为链表指针申请内存,我们大可以利用空闲内存的头部一个指针长度的内存储存指针,让它指向下一个空闲内存块,这样它们就能被串成一个自由链表了。而且还不用额外的内存消耗
哈希桶:因为不同大小的自由内存,我们要存在不同的自由链表里,所以我们还要把所有的自由链表管理起来。这里我们使用原生数组储存它们,然后把空闲内存块的大小映射到数组下标,再通过下标找到自由链表

运作模式大致如上,但是这个模式有两个明显的问题
- 前几个链表节点长度太短,根本存不下指针
- 自由链表的数量太多了,每个字节长度都分配一个自由链表的话,如果我们最大的空闲内存块有
256KB,那么我们会有256*1024个自由链表,光是存那么多指针就已经是极大的浪费了
所以我们要修改原来的一一对应的哈希规则,把一定范围的的内存大小对齐映射到同一个哈希桶中,这样就能减少哈希桶的总数。那么这个范围怎么定呢?肯定不能是定长,因为这样和原本相比的优化还是太少了。我们采用动态增长范围的方式,使不论多大的内存范围都能映射到合适的哈希桶,既不会浪费太多内存,又不会出现太多的哈希桶。
显然这样的动态规则实施起来变数很多,需要权衡好各种参数,这里直接采用由大佬总结出来的映射方案如下
| 一次试图申请的内存大小 | 对齐大小 | 映射的下标范围 | 实际获得的内存大小范围 |
|---|---|---|---|
| [1,128] | 8byte对齐 |
freelist[0,16) | 8,16,24, …128 |
| [128 + 1, 1024] | 16byte对齐 |
freelist[16,72) | 128 + 16, 128 + 16*2, 128 + 16*3, …1024 |
| [1024 + 1, 8 * 1024] | 128byte对齐 |
freelist[72,128) | 1024 + 128, 1024 + 128*2, 1024 + 128*3, …8*1024 |
| [8 * 1024 + 1, 64 * 1024] | 1024byte对齐 |
freelist[128,184) | 8*1024 + 1024, 8*1024 + 1024*2, …64*1024 |
| [64 * 1024 + 1, 256 * 1024] | 8 * 1024byte对齐 |
freelist[184,208) | 64*1024 + 8*1024, 64*1024 + 8*1024*2, …256*1024 |
这样的对齐方案,能够整体控制在最多10%左右的内碎片浪费,而哈希桶的总数也控制在了最多208个哈希桶。
下面是thread cache的例子
项目代码实现
基本的框架和核心原理已经在上面大致介绍了,具体细节我们在编写代码的时候再详细解释
类图结构

文件结构
- 头文件
Common.hConcurrentAlloc.hThreadCache.hCentralCache.hPageCache.hObjectPool
- cpp文件
ThreadCache.cppCentralCache.cppPageCache.cppUnitTest.cpp
Common.h
这个头文件主要用于存放一些公共使用的头文件和组件,比如全局变量,全局函数和工具类等
1 |