这是系列博客中的第二篇,导航如下
在Linux环境中,套接字(Socket)是一种用于进程间通信(IPC)的机制,但这里的进程,包括了同一网络下其它主机的进程 ,所以它被广泛应用于网络编程。它允许不同计算机上的进程或同一计算机上的不同进程之间进行数据交换。
由于此时我们的网络编程基础较少,所以本文的内容更偏向于实践 ,而不是原理。希望能在动手实践中加深对网络编程的熟悉程度,减少陌生感
在本文中,我们将:
知识铺垫:认识IP地址, 端口号, 网络字节序等网络编程中的基本概念(简略)socket API学习实现一个简单的UPD客户端/服务器
实现一个简单的TCP客户端/服务器(服务器包括单连接版本,多进程版本,多线程版本)
知识铺垫 理解源IP地址和目的IP地址 在数据包的头部中,包含两个IP地址,分别叫做源IP地址和目的IP地址
为什么要有两个IP地址?因为一般通过网络建立的通信都是双向的 ,而且一方接收请求后,一般还要把响应发送回去 ,所以含有两个IP地址才能方便地建立双向链接和通信。而且数据包每经过一个中间主机,都会被询问一次源和目的,就像唐僧常说的口头禅:“贫僧自东土大唐(源IP)而来,要到西天(目的IP)取经去”。
Audio
总结:通过IP协议,我们能找到唯一的主机 建立网络通信。
认识端口号 套接字(Socket)是一种用于进程间通信(IPC)的机制,然而IP协议只能指定唯一主机,想要进程间通信明显还不够。那在一台主机上,怎么标识唯一的进程呢?端口号(port)应运而生。
端口号是一个2字节16位的整数
正如上文所说,端口号用来标识本机的唯一进程
互斥性:为保证唯一性,一个端口号只能被一个进程占用
综上,通过IP地址+端口号便能够唯一地表示网络上的某一台主机的某一个进程。
端口号 与 进程ID 辨析 既然端口号port和进程ID都可以唯一地标识一个进程,那么这两者有何相似与差异呢?
进程ID:一个线程对应一个pid,一个pid对应一个线程,且操作系统就是用pid来调度线程的端口(port):端口号更像是一种被所有线程共享的互斥资源,每个都只有一份,但是同一个线程可以申请占用多个端口号,而一个端口号因为只有一份,只能被一个线程占用
源端口号和目的端口号 和源IP地址和目的IP地址配套使用,用于建立两台主机上特定的两个线程间的通信。
认识TCP协议和UDP协议
这里仅仅是有一个大概的了解,对协议原理更详细的较少将在后面的博客中提出
TPC协议 TCP(Transmission Control Protocol)是一种可靠的传输协议,特性如下
UDP协议 UDP(User Datagram Protocol)是一种不可靠的传输协议,特性如下
网络字节序 我们已经知道,内存中的多字节数据相对于内存地址有大端和小端之分, 磁盘文件中的多字节数据相对于文件中的偏移地址也有大端小端之分,网络数据流同样有大端小端之分 ,这给网络中不同主机的通信带来了困难, 那么如何定义网络数据流的地址,以保证不同机器能通过网络通信呢?
发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出
收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存
因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高地址
TCP/IP协议规定,网络数据流应采用大端字节序 ,即低地址高字节
不管这台主机是大端机还是小端机 , 都会按照这个TCP/IP规定的网络字节序来发送/接收数据如果当前发送主机是小端, 就需要先将数据转成大端; 否则就忽略, 直接发送即可
关于网络字节序的规则如上,显然这些都由程序员来做,效率还是太低了。
为了提高编程效率,同时也为了提高代码移植性,使同样的C代码在大端计算机和小端计算机上都能正常运行,可以调用以下头文件的库函数做网络字节序和主机字节序的转换
1 2 3 4 5 6 #include <arpa/inet.h> uint32_t htonl (uint32_t hostlong) ; uint16_t htons (uint16_t hostshort) ;uint32_t ntohl (uint32_t netlong) ; uint16_t ntohs (uint16_t netshort) ;
这些函数名很好记,h表示host,n表示network,l表示32位长整数,s表示16位短整数。
例如htons表示将16位的短整数从主机字节序转换为网络字节序,例如将port端口号转换后准备发送
如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回 如果主机是大端字节序,这些 函数不做转换,将参数原封不动地返回。
Socket编程 <sys/socket.h>提供了一系列套接字相关的接口,用于进行网络通信服务
基于Linux中一切皆文件的祖训,在套接字编程所创建的socket文件,也是作为文件管理的,socket文件也会申请自己的文件描述符,和其它打开的文件一起被管理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <sys/types.h> #include <sys/socket.h> int socket (int domain, int type, int protocol) ;int bind (int socket, const struct sockaddr *address, socklen_t address_len) ;int listen (int socket, int backlog) ;int accept (int socket, struct sockaddr* address, socklen_t * address_len) ;int connect (int sockfd, const struct sockaddr *addr, socklen_t addrlen) ;
常用接口如上,具体使用方法稍后在代码中展示
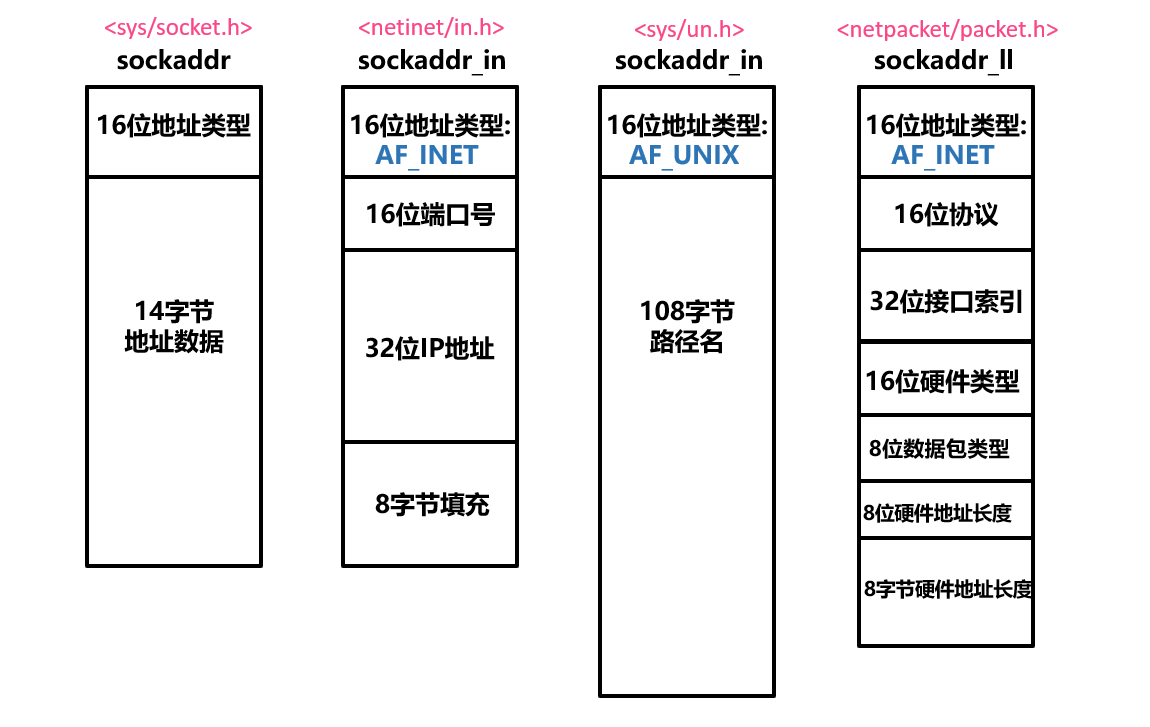
struct sockaddr*介绍 为什么不直接介绍struct sockaddr struct sockaddr 是个很简单的结构体,具有类似如下的结构
1 2 3 4 5 struct sockaddr { sa_family_t sa_family; char sa_data[14 ]; }
然而实际上在函数里用的也不是struct sockaddr,而是其它成员变量更丰富的结构体
它唯一的用处 就是在函数传参时防止类型不匹配 导致的报错,函数内部如何处理指针指向的内存,取决于sa_family的值。struct sockaddr*指针的作用有点类似于面向对象中父类指针 在函数传参中的作用
各种sockaddr_家族
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 struct sockaddr_in { sa_family_t sin_family; in_port_t sin_port; struct in_addr sin_addr ; }; struct sockaddr_in6 { sa_family_t sin6_family; in_port_t sin6_port; uint32_t sin6_flowinfo; struct in6_addr sin6_addr ; uint32_t sin6_scope_id; }; struct sockaddr_un { sa_family_t sun_family; char sun_path[108 ]; }; struct sockaddr_ll { uint16_t sll_family; uint16_t sll_protocol; int sll_ifindex; uint16_t sll_hatype; uint8_t sll_pkttype; uint8_t sll_halen; uint8_t sll_addr[8 ]; };
用途 接下来的介绍以struct sockaddr_in为例
1 2 3 4 5 struct sockaddr_in { sa_family_t sin_family; in_port_t sin_port; struct in_addr sin_addr ; };
struct sockaddr*指向的结构体 的用处对于服务器/客户端有所不同
对服务器提供服务
规定提供网络服务的ip格式(ipv4/ipv6)
规定提供网络服务的ip(因为一个电脑可以有多个ip,后文解释)
规定提供网络服务的端口号值
对服务器连接客户端
对客户端
in_addr的底层结构
1 2 3 4 5 typedef uint32_t in_addr_t ;struct in_addr { in_addr_t s_addr; };
in_addr用来表示一个IPv4的IP地址. 其实就是一个32位的无符号整数;
UDP通信编程 使用接口
int socket(int domain, int type, int protocol);
用于创建套接字文件,获取套接字文件描述符fd
domain规定域名通信协议,比如IPV4、IPV6、本地通信协议等type通信类型,SOCK_DGRAM表示面向数据报,SOCK_STREAM表示面向字节流,以及更多的类型,UDP通信使用SOCK_DGRAM protocol协议代码,可选内容取决于domain参数,可为0返回值为套接字文件的文件描述符
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
用于给指定sockfd绑定网络通信协议
sockfd文件描述符addr就是上面介绍的struct sockaddr的子类addrlen为addr指向结构体的大小返回值成功则返回0,失败则返回1
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,struct sockaddr *src_addr, socklen_t *addrlen);
sockfd文件描述符buf字节串缓冲区,用于存放接收到的字节流len缓冲区大小,防止越界访问flags为位图,可以传多个参数。本次介绍不传参,所以传入一个0src_addr指向储存消息源信息的结构体地址addrlen传入结构体的大小
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,const struct sockaddr *dest_addr, socklen_t addrlen);
sockfd文件描述符buf字节流缓冲区,用于存放待发送的字节串len待发送字节串的长度flags为位图,可以传多个参数。本次介绍不传参,所以传入一个0src_addr指向储存目标信息的结构体地址addrlen传入结构体的大小
看着接口很多,但其实在UDP协议下这几个接口的关系可以概括为下图:
接下来我们分别编写一下简单的UDP回显服务器
封装UdpServer 对于服务器,为了方便地进行代码复用等,把UdpServer的相关代码封装在UdpServer类内,并将类的声明和实现储存在udpServer.hpp中
基本结构
udpServer.hpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #pragma once #include <iostream> #include <sys/types.h> #include <sys/socket.h> #include <unistd.h> #include <string> #include <netinet/in.h> #include <arpa/inet.h> #include <string.h> #include <strings.h> #include <unordered_map> std::string defualt_ip = "0.0.0.0" ; uint16_t defualt_port = 25565 ; const int size = 1024 ; class UdpServer { public : UdpServer (uint16_t port = defualt_port,const std::string& ip = defualt_ip ) :_port(port),_ip(ip),_isRunning(false ) {} void Init () void CheckUser (const struct sockaddr_in& client,const std::string &clientip,uint16_t clientport) void Broadcast (const std::string& info,const std::string &clientip,uint16_t clientport) void Run () ~UdpServer () { if (_sockfd>0 ) { close (_sockfd); } } private : int _sockfd; bool _isRunning; uint16_t _port; std::string _ip; std::unordered_map<std::string,struct sockaddr_in> _ol_usr; };
一般ip和port都不是硬编码的,但这里只是示例程序,就不做的那么尽善尽美了。
特别的,当ip == '0.0.0.0'时,服务器会接收发往该服务器上所有可用IP地址的UDP数据包。这里再简单介绍下ip地址的选择(ipv4为例)
私网ip
常见的有192.xxx.xxx.xxx类型的ip地址
仅能进行私网(局域网)内的网络通信
公网ip
在互联网 中唯一的地址,任何接入互联网的机器都能访问到。
回环地址
最常用的是127.0.0.1,回环地址用于网络测试和调试,代表本地计算机
特殊ip地址,广播地址255.255.255.255,网络地址,如192.168.1.0,不在本次的讨论范围内
网卡数量与ip的关系:
单网卡: 如果服务器只有一块网卡,UDP 服务器通常会绑定到该网卡的 IP 地址。这意味着可用的 IP 地址数量为这块网卡的 IP 地址数量。
多网卡: 如果服务器有多块网卡,每块网卡都可以有一个或多个 IP 地址,UDP 服务器可以选择绑定到任一网卡的 IP 地址。因此,可用的 IP 地址数量将取决于所有网卡上配置的 IP 地址总数。
可以看到ip地址的关系挺复杂的,所以当出现服务器公网ip不能用于服务器绑定地址提供服务时,可以选择简化处理,选择0.0.0.0即可
Init() 用于初始化服务器:
创建套接字文件
准备sockaddr_in的内容
绑定sockaddr_in
代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void Init () _sockfd = socket (AF_INET,SOCK_DGRAM,0 ); if (_sockfd < 0 ) { printf ("[Fatal],socket creation failed,sockfd: %d\n" ,_sockfd); exit (SOCKET_ERR); } printf ("[Info],socket create succeeded , sockfd: %d\n" ,_sockfd); struct sockaddr_in local; bzero (&local,sizeof (local)); local.sin_family = AF_INET; local.sin_port = htons (_port);; local.sin_addr.s_addr = INADDR_ANY; if (bind (_sockfd,(const struct sockaddr *)& local,sizeof (local)) < 0 ) { printf ("Fatal,bind error,errno:%d ,err string: %s\n" ,errno,strerror (errno)); } printf ("Info,%s:%u bind succeeded\n" ,_ip.c_str (),_port); }
如果预先定好了传入的ip为0.0.0.0,则还有更简便的方法,直接使用宏INADDR_ANY给struct sockaddr_in.sin_addr.s_addr赋值,这样连地址转换函数都省略了
在Init()函数中,我们仅仅实现了对套接字的绑定,关于收发udp数据报,我们将在Run()函数内实现。但为了提高代码封装性,在写其它接口前,我们先写两个工具函数
CheckUser() 检查是否是新用户接入
1 2 3 4 5 6 7 8 9 void CheckUser (const struct sockaddr_in& client,const std::string &clientip,uint16_t clientport) auto iter = _ol_usr.find (clientip); if (iter == _ol_usr.end ()) { printf ("Info,[%s] added to oline user\n" ,clientip.c_str ()); _ol_usr.insert ({clientip,client}); } }
Broadcast() 回显服务器执行功能,像所有客户端广播信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void Broadcast (const std::string& info,const std::string &clientip,uint16_t clientport) std::string msg = "[" ; msg+=clientip; msg+=":" ; msg+=std::to_string (clientport); msg+="]# " ; msg+= info; for (const auto &user:_ol_usr) { printf ("Info,Broadcast\n" ); socklen_t len = sizeof (user.second); sendto (_sockfd,msg.c_str (),msg.size (),0 ,(const sockaddr*)&(user.second),len); } }
Run() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void Run () printf ("Info,Server started running...\n" ); _isRunning = true ; char inbuffer[size] = {0 }; while (_isRunning) { sleep (1 ); struct sockaddr_in client; socklen_t len = sizeof (client); ssize_t n = recvfrom (_sockfd,inbuffer,sizeof (inbuffer)-1 ,0 ,(struct sockaddr *) &client , &len); if (n<0 ) { printf ("Warning,recvfrom error,errno:%d ,err string: %s\n" ,errno,strerror (errno)); } inbuffer[n] = 0 ; uint16_t clientport = ntohs (client.sin_port); std::string clientip = inet_ntoa (client.sin_addr); std::string info = inbuffer; CheckUser (client,clientip,clientport); Broadcast (info,clientip,clientport); printf ("Info, Server get a msg! [%s:%u]: %s\n" ,clientip.c_str (),clientport,inbuffer); } }
编写Main.cpp 因为启动服务器还需要一个源文件形成可执行文件,所以这边编写一个Main.cpp
就是实例化了一个UdoServer对象并启动服务而已
1 2 3 4 5 6 7 8 9 10 11 #include <memory> #include <iostream> #include "udpServer.hpp" int main (int argc,char * args[]) std::unique_ptr<UdpServer> svr (new UdpServer()) ; svr->Init (); svr->Run (); return 0 ; }
编写Client.cpp 我们来写一个简单的udp客户端
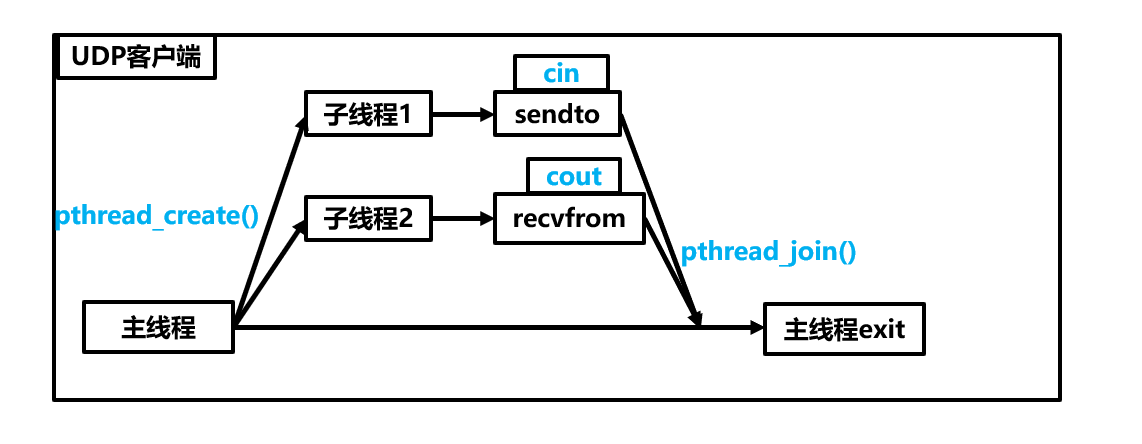
下面要用到多线程🔗 防止进程在阻塞等待用户输入时,无法立即输出接收到的udp数据报
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 #include <iostream> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <unistd.h> #include <strings.h> #include <pthread.h> struct ThreadData { struct sockaddr_in server; int sockfd; }; void *recv_msg (void * args) char buffer[1024 ] = {0 }; struct ThreadData * td = (struct ThreadData*)args; while (true ) { struct sockaddr_in temp; socklen_t len = sizeof (temp); ssize_t s = recvfrom (td->sockfd,buffer,1023 ,0 ,(struct sockaddr*)&temp,&len); if (s>0 ) { buffer[s] = 0 ; std::cout<<buffer<<std::endl; } } } void *send_msg (void * args) struct ThreadData * td = (struct ThreadData*)args; std::string msg; socklen_t len = sizeof (td->server); while (true ) { std::cout<<"Please Enter@" ; std::getline (std::cin,msg); sendto (td->sockfd,msg.c_str (),msg.size (),0 ,(struct sockaddr*)&td->server,len); } } int main () std::string serverip ("127.0.0.1" ) ; uint16_t serverport = 25565 ; struct ThreadData td; bzero (&td.server,sizeof (td.server)); td.server.sin_family = AF_INET; td.server.sin_port = htons (serverport); td.server.sin_addr.s_addr = inet_addr (serverip.c_str ()); td.sockfd = socket (AF_INET,SOCK_DGRAM,0 ); if (td.sockfd<0 ) { std::cout<<"socket err\n" <<std::endl; return -1 ; } pthread_t recvr,sender; pthread_create (&recvr,nullptr ,recv_msg,&td); pthread_create (&sender,nullptr ,send_msg,&td); pthread_join (recvr,nullptr ); pthread_join (sender,nullptr ); close (td.sockfd); return 0 ; }
地址转换函数 在写客户端时指定客户端就不能用INADDR_ANY了,因为要指定具体的ip地址。
我们知道(IPv4地址)ip其实是一个32位无符号整数,而我们平时使用点分十进制表示,结构体的struct sockaddr_in.sin_addr.s_addr确正是32位无符号整数,为可以自己把字符串转成整数,当然也可以调用地址转换函数来执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> int inet_aton (const char *const_str_ptr, struct in_addr *inaddr_ptr) ;in_addr_t inet_addr (const char *const_str_ptr) ;int inet_pton (int addr_family, const char *src_str, void *dst_addr) ;char *inet_ntoa (struct in_addr in) ;const char *inet_ntop (int addr_family, const void *src_addr, char *dst_str, socklen_t size) ;
其中inet_pton和inet_ntop不仅可以转换IPV4的in_addr,还可以转换IPV6的in6_addr,因此函数接口使用了void* addrptr参数
关于inet_ntoa 这个函数返回了一个char*,那么我们需不需要手动释放它呢?我们来查看一下man手册
可以看到,返回的字符串并不在堆区上,而是在静态区。这将会导致一个问题 ,如果直接使用返回的地址,而不是另外拷贝一份字符串,原地址指向的字符串将会有随时被修改的风险。同时,这也严重影响了线程安全性。我们来写一小段代码验证man手册的说法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> #include <netinet/in.h> #include <arpa/inet.h> int main () { struct sockaddr_in addr1 ; struct sockaddr_in addr2 ; addr1.sin_addr.s_addr = 0 ; addr2.sin_addr.s_addr = 0xffffffff ; char *ptr1 = inet_ntoa(addr1.sin_addr); char *ptr2 = inet_ntoa(addr2.sin_addr); printf ("ptr1: %s address: %p\nptr2: %s address: %p\n" , ptr1, ptr1,ptr2,ptr2); return 0 ; }
输出结果如下
可以看到,ptr1和ptr2的值是一样的,所以指向的字符串也是一样的。而ptr1本应该储存了"0.0.0.0",输出结果严重不符合预期
所以为了安全性问题 ,更建议使用 inet_ntop,因为它使用了用户提供的缓冲区来存储字符串,而各个线程的栈区是独立的,可以独立地存储字符串。
编写makefile 1 2 3 4 5 6 7 8 9 10 11 12 .PHONY :allall:udpServer udpclient udpServer:Main.cpp g++ -o $@ $^ -std=c++11 udpclient:UdpClient.cpp g++ -o $@ $^ -std=c++11 -lpthread .PHONY :cleanclean: rm -f udpServer udpclient
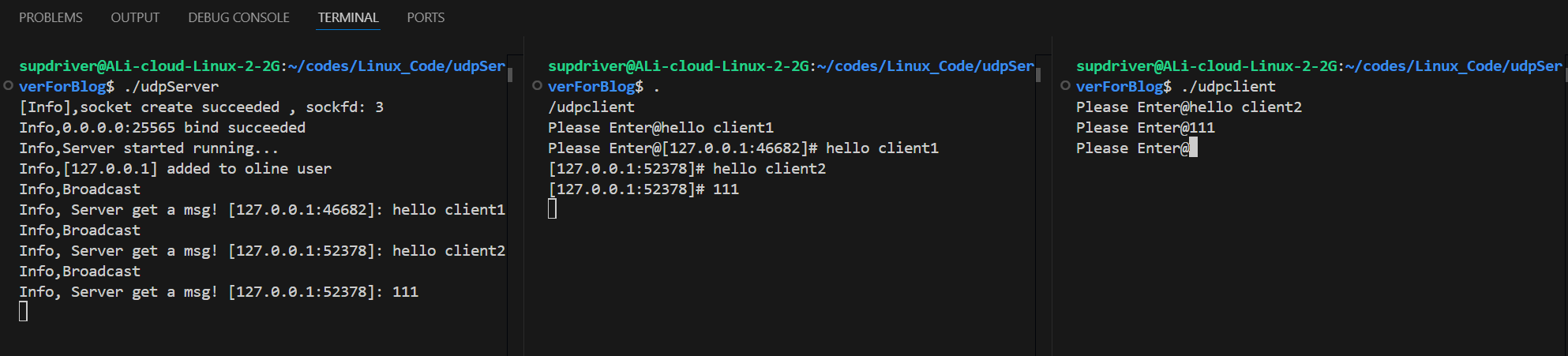
测试通信效果
如上图所示,~~~除了输入输出有些顺序混乱~~~,客户端和服务端的回显通信服务工作得很好。
UDP通信小结 UDP通信协议是一种面向数据报的不可靠的通信协议,一个数据报如果只读了一部分,剩下的只会被直接丢弃。但是它使用简单,建立连接的速率也比接下来要介绍的TCP通信协议要快
TCP通信编程 使用接口:
首先还是创建套接字文件和绑定struct sockaddr
int socket(int domain, int type, int protocol);
用于创建套接字文件,获取套接字文件描述符fd
domain规定域名通信协议,比如IPV4、IPV6、本地通信协议等type通信类型,SOCK_DGRAM表示面向数据报,SOCK_STREAM表示面向字节流,TCP通信使用SOCK_STREAM protocol协议代码,可选内容取决于domain参数,可为0返回值为套接字文件的文件描述符
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
用于给指定sockfd绑定网络通信协议
sockfd文件描述符addr就是上面介绍的struct sockaddr的子类addrlen为addr指向结构体的大小返回值成功则返回0,失败则返回1
int listen(int sockfd, int backlog);
声明指定socket文件处于监听状态,最多允许有backlog个客户端处于连接等待状态
sockfd文件描述符backlog 最多允许有backlog个客户端处于连接等待状态返回值成功则返回0,失败则返回1
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
服务端(默认阻塞)等待与客户端进行三次握手后的连接
连接成功后会创建新的 专门用于通信的套接字文件描述符并返回
sockfd用于监听的sockfd文件描述符addr输出型参数,一个缓冲区,指向储存消息源信息的结构体地址addelen传入结构体的大小返回值用于与特定客户端网络通信的文件描述符
int connect(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
客户端(默认阻塞)等待与指定服务端建立TCP连接
连接成功后会创建新的 用于通信的套接字文件描述符并返回
sockfd用于建立通信创建的套接字文件addr储存了待连接的服务端的信息addrlen传入结构的大小
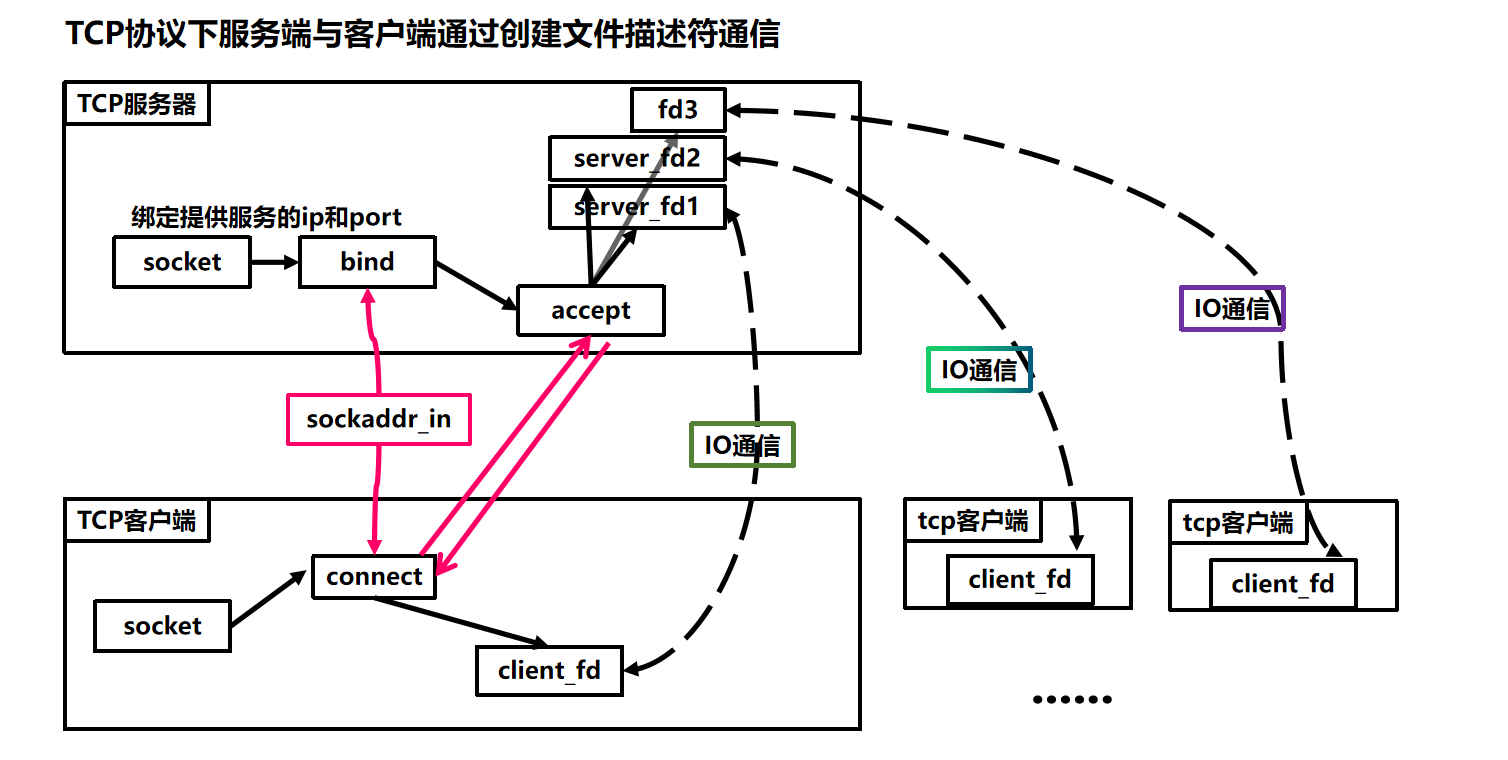
对接口的使用概览图如下
编写TCP回显服务器 我们还是来写个简单的程序来实践一下这些接口。
封装TCPSocket类 因为监听和连接用的TCPSocket与具体的IO通信使用的sockfd是可以分离的(不共用文件描述符),所以更适合使用C++封装成类
类声明如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #pragma once #include <stdio.h> #include <string> #include <unistd.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <fcntl.h> #include <string.h> #include <sys/types.h> class TCPSocket { public : TCPSocket (int fd = -1 ) :_sock_fd(fd){} bool Socket () bool Bind (const std::string& ip,uint16_t port) const bool Listen (int backlog = 5 ) const int Accept (std::string* client_ip=nullptr ,uint16_t * client_port = nullptr ) const int Connect (const std::string&server_ip,const uint16_t server_port) const void Close () { close (_sock_fd); } ~TCPSocket () { Close (); } private : int _sock_fd; };
其中Socket(),Bind(),Listen()较为简单,直接实现即可。唯一要注意的是Listen要提供backlog参数将其传递给内部的listen函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public : TCPSocket (const std::string& ip,uint32_t port) :_sock_fd(-1 ){} bool Socket () { _sock_fd = socket (AF_INET,SOCK_STREAM,0 ); if (_sock_fd < 0 ) { perror ("socket" ); return false ; } printf ("info: open socket fd :%d\n" ,_sock_fd); return true ; } bool Bind (const std::string& ip,uint16_t port) const { struct sockaddr_in addr_in; addr_in.sin_family = AF_INET; addr_in.sin_addr.s_addr = inet_addr (ip.c_str ()); addr_in.sin_port = htons (port); int ret = bind (_sock_fd,(const struct sockaddr*)&addr_in,sizeof (addr_in)); if (ret<0 ) { perror ("bind" ); return false ; } return true ; } bool Listen (int backlog = 5 ) const { int ret = listen (_sock_fd,backlog); if (ret < 0 ) { perror ("listen" ); return false ; } return true ; }
接下来是封装accept(),我们准备让它接收连接请求,预处理,然后返回所需的信息。对于Accept()我们主要需要从里面获取客户端ip,客户端port,对应的文件描述符。我们设计让函数返回文件描述符,即在最后返回accept的返回值,与被封装的接口保持一致。至于剩下的两个参数,我们使用输出型参数来输出ip和port
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public : int Accept (std::string* client_ip=nullptr ,uint16_t * client_port = nullptr ) { struct sockaddr_in client_addr; socklen_t len = sizeof (client_addr); int new_fd = accept (_sock_fd,(struct sockaddr*)&client_addr,&len); if (new_fd < 0 ) { perror ("accept" ); return new_fd; } printf ("info, accept fd: %d\n" ,new_fd); if (client_ip !=nullptr ) { char buffer[128 ] = {0 }; inet_ntop (AF_INET,&client_addr,buffer,sizeof (client_addr)); *client_ip = buffer; } if (client_port != nullptr ) { *client_port = ntohs (client_addr.sin_port); } return new_fd; }
Connect()成员函数则是对connect函数进行封装,使其更加易用,只需传入服务器ip和端口号,然后接收其返回值即可获得用于通信的文件描述符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int Connect (const std::string&server_ip,const uint16_t server_port) if (server_ip.empty ()) { printf ("ip不可为空\n" ); return -1 ; } struct sockaddr_in server_addr; server_addr.sin_family = AF_INET; server_addr.sin_port = htons (server_port); server_addr.sin_addr.s_addr = inet_addr (server_ip.c_str ()); int ret = connect (_sock_fd,(const struct sockaddr*)&server_addr,sizeof (server_addr)); if (ret<0 ) { perror ("connect" ); } return ret; }
封装TCPEchoServer类 封装好套接字类后,我们就要来实践具体的通信部分了。在概念设计上,即使是最简单的回显服务器,明显单线程已经不能满足需求了,因为监听,连接,收发信息常常会把线程阻塞住,所以我们选择使用多线程或者多进程技术来优化程序。关于更高效的网络通信IO有很多内容可以展开讲,但不是本文的主题,所以放到以后的文章中
本文选择较为简单的多进程技术
基本结构如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include "TCPSocket.hpp" #include <unordered_set> #include <vector> #include <sys/wait.h> class TCPEchoServer { public : TCPEchoServer (const std::string& ip,const uint16_t port) :_ip(ip),_port(port){} void run () private : void broadcast (const std::string& ip,const uint16_t port) void child_loop (int fd) public : ~TCPEchoServer () { _socket.Close (); for (auto fd:_clients) { close (fd); } } private : std::string _ip; uint16_t _port; TCPSocket _socket; std::unordered_set<int > _clients; };
可以看到,TCPEchoServer类内管理了许多文件描述符,为了防止文件描述符泄漏,析构函数一定要记得把不需要的文件描述符都关闭了。
接下来我们先实现broadcast和child_loop,最后再实现run
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private : void broadcast (const std::string& ip,const uint16_t port) { std::string who; who+="[" ; who+=ip; who+=":" ; who+=std::to_string (port); who+="]" ; std::string msg (who) ; msg+="Entered Server\n" ; std::vector<int > del_list; for (auto fd:_clients) { int ret = write (fd,msg.c_str (),msg.size ()); if (ret == 0 ) { printf ("%s disconnected\n" ,who.c_str ()); del_list.push_back (fd); } } for (auto fd:del_list) { close (fd); _clients.erase (fd); } }
这里要清除写端关闭的文件描述符,但是在使用迭代器遍历(for…auto… )时,修改容器是很危险的,所以我们用到了缓冲区的思想,把待删除的文件描述符存在vector中,最后再集中关闭和移除出_clients;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 private : void child_loop (int fd) { while (true ) { char buffer[128 ]; int n =read (fd,buffer,sizeof (buffer)-1 ); if (n<=0 )return ; buffer[n] = '0' ; n = write (fd,buffer,sizeof (buffer)-1 ); if (n<=0 )return ; } }
子进程(其实是孙子)的工作是一个死循环,持续提供服务。当连接关闭时,它就会自动退出循环。
最后来实现run函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public : void run () { if (_socket.Socket () == false ) return ; if (_socket.Bind (_ip,_port) == false ) return ; if (_socket.Listen () == false )return ; while (true ) { std::string client_ip; uint16_t client_port; int client_fd = _socket.Accept (&client_ip,&client_port); if (client_fd < 0 ) { sleep (1 ); continue ; } broadcast (client_ip,client_port); _clients.insert (client_fd); pid_t pid = fork(); if (pid == 0 ) { _socket.Close (); if (fork() != 0 ) exit (0 ); child_loop (client_fd); close (client_fd); exit (0 ); } else { pid_t rid = waitpid (pid,nullptr ,0 ); (void ) rid; } } }
一般创建了子进程之后,父进程还要等待子进程退出并回收子进程的资源。而默认情况下的等待是阻塞的,当然我们可以设置成为非阻塞轮询,但我们也可以讨巧地创建孙子进程 ,让子进程立即退出并被主进程回收,这时孙子进程变成孤儿进程,由PID==1的进程进行回收资源
我们再简单地写一下Main.cpp
1 2 3 4 5 6 7 8 9 10 11 12 #include <iostream> #include <memory> #include "TCPEchoServer.hpp" int main () std::shared_ptr<TCPEchoServer> ptr (new TCPEchoServer("127.0.0.1" ,8888 )) ; ptr->run (); return 0 ; }
编写TCPClient客户端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include "TCPSocket.hpp" #include <iostream> #include <thread> using namespace std;void Recv (void * arg) int fd = *(int *)arg; while (true ) { char buffer[128 ]; int n = read (fd,buffer,sizeof (buffer)-1 ); if (n == 0 ){printf ("disconnected\n" );break ;} if (n<0 ){printf ("read error\n" );break ;} buffer[n] = '\0' ; cout<<buffer<<endl<<endl; } } void Send (void * arg) int fd = *(int *)arg; string line; while (true ) { getline (cin,line); int n = write (fd,line.c_str (),line.size ()); if (n == 0 ) { printf ("disconnected\n" ); break ; } if (n<0 ) { printf ("write error\n" ); break ; } } } int main () TCPSocket conSocket; conSocket.Socket (); int fd = conSocket.Connect ("127.0.0.1" ,8888 ); thread t1 (Recv,&fd) ; thread t2 (Send,&fd) ; t1. join (); t2. join (); return 0 ; }
这里使用了C++线程库,比C语言的更加简单易用。
编写makefile 1 2 3 4 5 6 7 8 9 10 11 12 .PHONY :allall:server client server:Main.cpp g++ -o $@ $^ -std=c++11 client:TCPClient.cpp g++ -o $@ $^ -std=c++11 .PHONY :cleanclean: rm -f server client
这里依然使用了点小技巧(指.PHONY:all)