初阶】初识Redis与指令学习
认识Redis
Redis 是⼀种基于键值对(key-value)的NoSQL数据库,同时它也是一款高性能的内存数据库,与很多键值对数据库不同的是,Redis中的值可以是由string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、HyperLogLog、GEO(地理信息定位)等多种数据结构和算法组成,因此Redis可以满⾜很多的应⽤场景,⽽且因为Redis会将所有数据都存放再内存中,所以它的读写性能⾮常惊⼈。
Redis的八大特性
Redis有着八大令人青睐的特性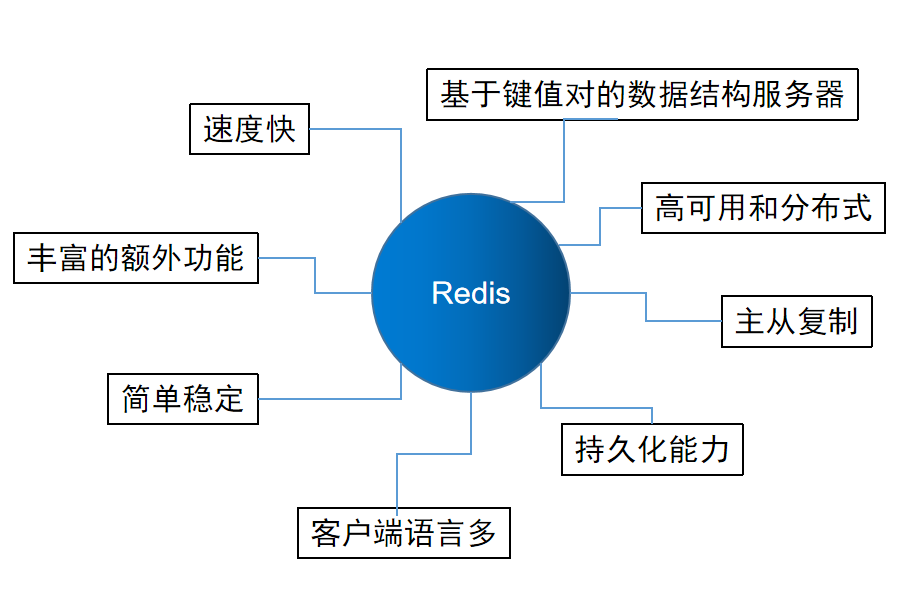
1. 速度快
Redis最突出的特点就是速度快,官⽅给出的读写性能可以高达10万/秒,而保证它能有如此之高性能的基础,主要有如下四点:
基于内存:相比于传统数据库基于外存上存储的数据库文件,Redis所有的数据都是存放在内存中的,由于内存和外存的读写速率差异是以数量级论的,所以Redis相比之下速度特别快C语言实现:C语言本身就具有高性能的特点单线程数据处理: 单线程的处理方式避免了锁竞争造成的性能损耗高性能的代码实现
2. 基于键值对的数据结构服务器
尽管Redis键值对中的键固定为字符串类型,Redis提供了更为丰富的键值对中的值类型,包括基础的string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)和更为高级的Bitmaps(位图)、HyperLogLog、GEO(地理信息定位)等,大大提高了Redis的可用范围
3.丰富的功能服务
除了基本的数据库功能,Redis还提供了额外的功能
键过期功能:可以用来实现缓存发布订阅功能:可以用来实现消息系统支持Lua脚本功能:可以利用Lua创造出新的Redis指令提供简单的事务功能流水线(Pipline)功能:客户端能将一批命名一次性传到Redis,通过减少网络IO次数的方式减少开销
4.简单稳定
Redis的简单体现在三个方面
源码代码量少:即使迭代到7.2.4版本,它也仅有约12万行的代码,与其它数据库产品相比属于极致精简单线程模型:单线程的数据处理模型使得程序结构十分简单操作系统依赖性小:Redis不依赖操作系统中的类库
简单也使得Redis具备相当的稳定性,能够使得在大量使用的过程中,很少出现因为Redis自身bug导致宕机的情况
2023年统计
| 数据库 | 代码行数 |
|---|---|
| Redis | ≈12万 |
| Memcached | ≈8.5万 |
| MySQL | ≈350万 |
| MongoDB | ≈420万 |
5. 客户端语言众多
Redis 提供了简单的TCP通信协议,很多编程语⾔可以很⽅便地接⼊到Redis,并且由于Redis受到社区和各⼤公司的⼴泛认可,所以⽀持Redis的客⼾端语⾔也⾮常多,⼏乎涵盖了主流的编程语⾔,例如C、C++、Java、PHP、Python、NodeJS等
像是未来我们要使用的redis-plis-plus就是用于编写C++客户端十分好用的开源项目
6. 持久化
因为内存有掉电易失性,对数据的存储来说是不安全,为此Redis提供了两种持久化策略RDB和AOF,它们可以将内存的数据保存到硬盘中,借此保证了数据的可持久性
7. 主从复制
Redis提供了复制功能,复制功能是分布式Redis的基础,它能够大大提高Redis的并发能力
8.高可用和分布式
Redis 提供了⾼可⽤实现的Redis哨兵(RedisSentinel),能够保证Redis结点的故障发现和故障⾃动转移。也提供了Redis集群(RedisCluster),是真正的分布式实现,提供了⾼可⽤、读写和容量的扩展性
Redis使用场景
Redis有很多茶昂见的应用
- 缓存
- Redis提供了键值过期时间
- Redis提供了最大内存控制和内存溢出后的淘汰策略
- 排行榜系统
- Redis提供了列表和有序集合的数据结构
- Redis提供了可供复杂维度计算排行榜的功能
- 计数器应用
- Redis天然支持计数功能且性能很好,可以应对高并发量访问
- 社交网络
- Redis可以很好地应对社交网站的高访问量问题下对
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等的服务提供
- Redis可以很好地应对社交网站的高访问量问题下对
- 消息队列系统
- 消息队列系统可以说是⼀个⼤型⽹站的必备基础组件,因为其具有业务解耦、⾮实时业务削峰等特性。Redis提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列⽐还不够⾜够强⼤,但是对于⼀般的消息队列功能基本可以满⾜
安装Redis
Ubuntu安装
使用apt源安装
1 | sudo apt update |
镜像安装
这里对在宿主机上的Redis安装不作重点介绍,仅作为客户端的安装,对于服务端的安装,则是使用更易于搭建集群的从docker平台的Redis镜像启动容器,我们通过连接容器来使用Redis服务
Redis重要文件及作用
相关的命令/脚本
1 | /usr/bin/redis-benchmark |
redis-server是 Redis 服务器程序,其余的⼏个例如:redis-check-aof、redis-check-rdb、redissentinel 也都是redis-server 的软链接。redis-check-aof是修复AOF⽂件⽤的⼯具,redis-check-rdb是修复RDB⽂件的⼯具,redis-sentinel是Redis哨兵程序
redis-cli是在我们学习阶段需要频繁⽤到的⼀个命令⾏客⼾端程序redis-benchmark⽤于对Redis做性能基准测试的⼯具。redis-shutdown是⽤于停⽌Redis的专⽤脚本
配置文件
1 | /etc/redis-sentinel.conf |
/etc/redis.conf是 Redis 服务器的配置⽂件。/etc/redis-sentinel.conf是RedisSentinel的配置⽂件。
RedisSentinel用于主从切换,替换出故障的主节点
持久化文件存储目录
1 | /var/lib/redis/ |
Redis 持久化⽣产的RDB和AOF⽂件都默认⽣成于该⽬录下。在容器构建中可以对此目录创建创建存储卷
日志文件目录
1 | /var/log/redis/ |
/var/log/redis/ ⽬录下会保存Redis运⾏期间⽣产的⽇志⽂件,默认按照天进⾏分割,并且会将⼀定⽇期的⽇⼦⽂件使⽤gzip格式压缩保存。可以使⽤任意⽂本编辑器打开
Redis服务端
高效的单线程模型
虽然作为C/S架构,一个Redis服务端能似乎能”同时”和多个客户端交互,实际上服务端仍然是单线程串行执行所有事务的。但是就这么一个单线程的串行是怎么做到每秒万级别的处理能力呢?其原因主要有三点
纯内存访问:内存的响应时长大约为100纳秒,这是Redis达到每秒万级别访问的重要基础非阻塞IO:Redis有着高效的网络IO机制,Redis使⽤epoll作为I/O多路复⽤技术的实现,再加上Redis⾃⾝的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在⽹络I/O上浪费过多的时间。戳我去epoll的介绍博客🔗- 单线程避免了线程切换和锁竞争产生的消耗
数据结构和内部编码
type 命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是Redis对外的数据结构。
但若深入底层实现,实际上Redis针对每种数据结构都有⾃⼰的底层内部编码实现,⽽且是多种实现,这样Redis会在合适的场景选择合适的内部编码。
| 数据结构 | 内部编码 |
| string | row |
| int | |
| embstr | |
| hash | hashtable |
| ziplist | |
| list | linkedlist |
| ziplist | |
| set | hashtable |
| intset | |
| zset | skiplist |
| ziplist |
可以看到每种数据结构至少都有两种以上的内部编码实现。若要查看当前key对应的数据结构的内部编码方式,可以使用命令(不区分大小写)object encoding查询
Redis这样的设计有两大好处:
- 解耦合,对内部编码的优化和改动,都不影响对外数据结构的使用,一方面外部使用更为简单方便,另一方面内部实现的维护更为独立。
- 多场景适应:多样的内部编码实现可以在不同常见下发挥各自的优势,Redis能够自动选择合适的内部编码方式,保持Redis的高效性。
Redis命令行客户端
在安装Redis时,它自带安装了一个命令行客户端工具,Redis是一个典型的C/S架构的应用服务,因此只要能对接redis-server的网络API,都能作为Redis的客户端。redis-cli就是官方提供的命令行工具。它有两种交互方式
- 前台交互方式:这是一种类似通过
mysql -u指令连接MySQL的连接方式,指令格式是redis-cli -h {host} -p {port},连接成功后便可以持续地使用Redis指令一直交互 - 命令方式:这就是第一种方式在后面加上要运行的
Redis指令,redis-cli -h {host} -p {port} {command}可以直接得到命令的返回结果,而不会进入交互模式
注,使用默认端口6379时,可以省略端口号,使用默认本地环回ip 127.0.0.1时,可以省略主机地址
数据库结构
Redis提供了几个面向Redis数据库的操作,分别是dbsize、select、flushdb、flushall命令,
SELECT切换数据库
语法
1 | SELECT dbIndex |
Redis默认配置中有16个数据库,但是不同于一般的使用命名区分,Redis数据库只使用下标区分不同的数据库。Redis中不同的数据库是完全隔离的。但由于Redis本身是单线程模型,单Redis多数据库显然不如多Redis但数据库的性能。
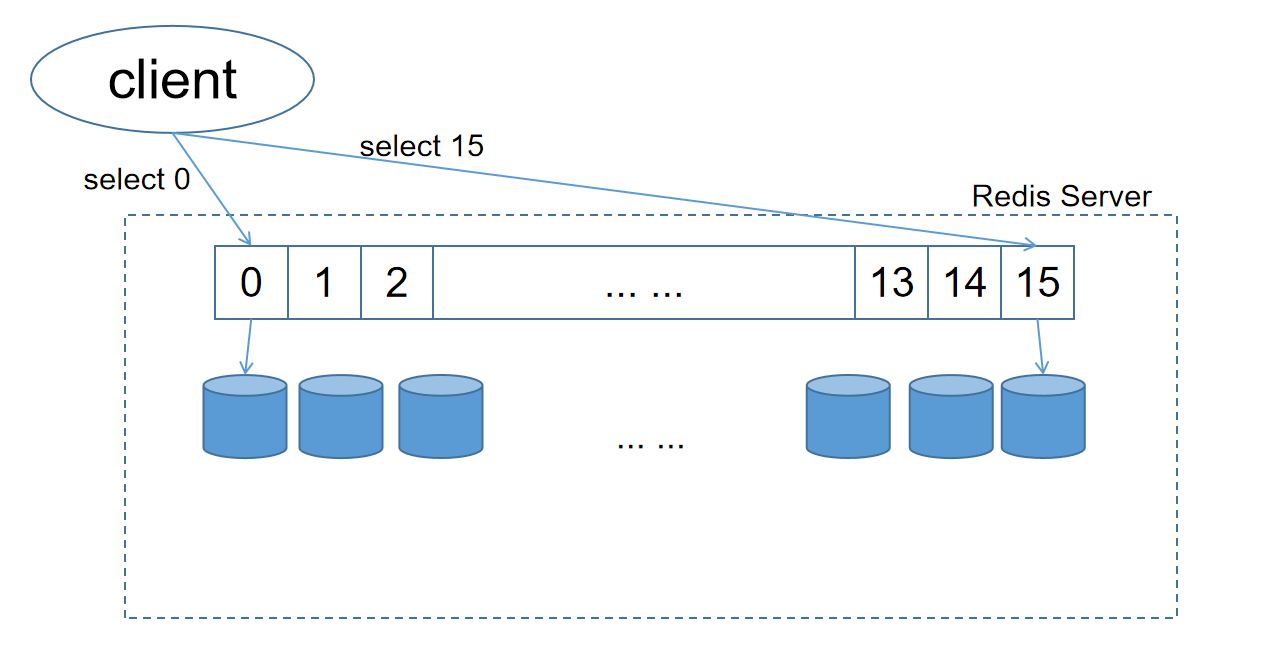
清除数据库
flushdb/flushall可以用于删库清理一个或所有数据库的数据。
基本全局命令
FLUSHALL
虽然是介绍的第一个指令,但是慎用!慎用!慎用!,它会清除掉Redis内的所有数据库的键值对
相应的还有一个FLUSHDB用于清除当前数据库的所有键值对。慎用!慎用!慎用!
KEYS
返回所有匹配格式串的key,它使用的匹配模式类似正则表达式,但是更为简单
| 功能 | Redis模式 | 正则表达式 |
|---|---|---|
| 任意字符 | * |
.* |
| 单个字符 | ? |
. |
| 字符集合 | [aeiou] |
[aeiou] |
| 范围匹配 | [a-z] |
[a-z] |
| 反向匹配 | [^abc] |
[^abc] |
| 精确匹配 | \* (转义星号) |
\* |
| 分组匹配 | ❌ 不支持 | (ab|cd) |
| 量词 | ❌ 不支持 | {n,m} + ? |
时间复杂度:O(N),需要遍历所有的KEY
注:因为其较高的时间复杂度,慎用keys *,因为Redis是单线程模型,过大的任务量会阻塞Redis服务
SCAN
SCAN指令用于渐进式遍历键,用于解决直接使用KEYS指令获取键可能出现的阻塞问题。它用起来类似于迭代器。
语法:
1 | SCAN cursor [MATCH pattern] [COUNT count] [TYPE type] |
- 这个cursor是本次指令开始遍历的下标
- 首次scan应当从0开始
- 每次scan会返回下次scan的cursor值
- 当scanf返回的下次位置为0时,遍历结束
- count只是个建议值,实际返回的数量可能会有差别
返回值:返回值包含两项
- 第一项: 下次scan应使用的cursor
- 第二项: 本次查询到的键值对列表
衍生:针对其它类型的数据结构,也有
HSCAN、SSCAN、ZSCAN等命令
EXISTS
判断某个或某几个key是否存在
- 时间复杂度:O(1)
- 返回值: key存在的个数
示例:1
2
3
4
5
6
7
8
9
10127.0.0.1:6379> SET key1 "hi"
OK
127.0.0.1:6379> EXISTS noSuchKey
(integer) 0
127.0.0.1:6379> EXISTS key1
(integer) 1
127.0.0.1:6379> SET key2 "hh"
OK
127.0.0.1:6379> EXISTS key1 key2 noSuchKey
(integer) 2
DEL
删除指定的key ,(可以是多个
- 时间复杂度:O(1)
- 返回值:删除key的个数
EXPIRE
为已存在的指定key设置秒级过期时间,注:毫秒级的可以用PEXPIRE
- 时间复杂度:O(1)
- 返回值:成功设置key的数量
且重复设置会按从最后一条EXPIRE指令开始,按最后一条设置的时间计时
TTL
获取指定key的当前过期时间(秒级),毫秒级可以用PTTL
- 返回值:剩余时间,若key不存在,则返回
-2
键的过期机制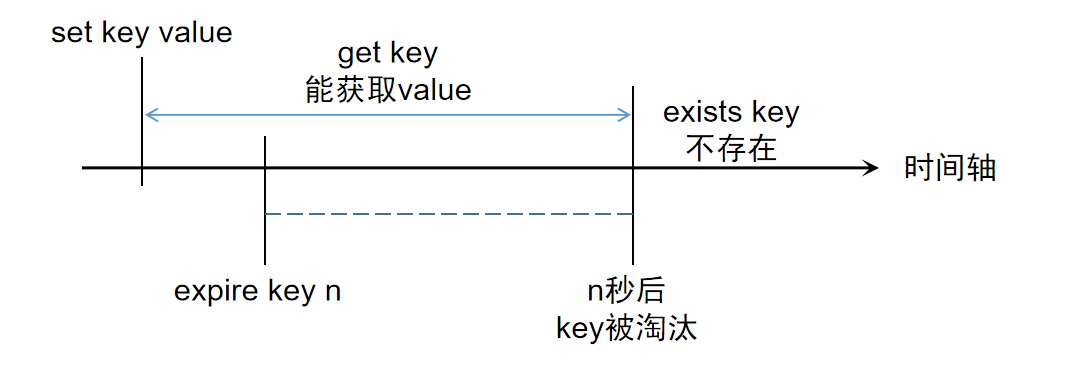
EXPIRE和TTL的使用示例
1 | 127.0.0.1:6379> SET key1 111 |
TYPE
返回key对应的数据类型
- 时间复杂度: O(1)
OBJECT ENCODING
上文已经介绍过,可以用于查询key的内部编码方式
- 时间复杂度: O(1)
Redis五种数据结构
String字符串
| 数据结构 | 内部编码 |
| string | row |
| int | |
| embstr |
字符串类型是Redis最基础的数据类型,字符串类型的值实际可以是:
- 字符串:包含⼀般格式的字符串或者类似JSON、XML格式的字符
- 数字: 可以是整型或者浮点型
- ⼆进制流数据:例如图⽚、⾳频、视频等。不过⼀个字符串的最⼤值不能超过512MB。
由于Redis内部存储字符串完全是按照⼆进制流的形式保存的,所以Redis是不处理字符集编码问题的,客⼾端传⼊的命令中使⽤的是什么字符集编码,就存储什么字符集编码。
接下来开始介绍常见指令
SET
将string 类型的value设置到key中。如果key之前存在,则覆盖,⽆论原来的数据类型是什么。之前关于此key的TTL也全部失效
语法:
1 | SET key value [expiration EX seconds|PX milliseconds] [NX|XX] |
注:方括号内的都是可选项
- 时间复杂度O(1)
- 可选项
EX seconds使⽤秒作为单位设置key的过期时间。PX milliseconds使⽤毫秒作为单位设置key的过期时间。NX只在key不存在时才进⾏设置,即如果key之前已经存在,设置不执⾏。XX只在key存在时才进⾏设置,即如果key之前不存在,设置不执⾏。
基于上面的可选项,SET指令也能衍生出SETNX,SETEX,SETPEX等命令
- 返回值
- 如果设置成功,返回OK。
- 如果由于SET指定了NX或者XX但条件不满⾜,SET不会执⾏,并返回(nil)。
MSET
Muilti SET,一次指令设置多个string类型的键值对,可以有效地减少网络IO次数
- 时间复杂度: O(N),N为设置key的规模数量
- 返回值: 固定为OK
GET
获取key对应的value。如果key不存在,返回nil。如果value的数据类型不是string,会报错,返回值为报错信息
- 时间复杂度O(1)
- 返回值
成功:key对应的Value不存在:nil类型错误:报错信息
MGET
Multi GET,一次获取多个key的Value,key之间用空格分隔
- 时间复杂度: O(N),N为查询key的规模数量
- 返回值
- 对应value的列表
- 列表值:
- 类型匹配时为字符串内容
- 类型不匹配时为
nil
- 列表值:
- 对应value的列表
计数命令(INCR等命令)
INCR将key对应的string表⽰的数字加⼀INCRBY将key对应的string表⽰的数字加上对应的值DECR将key对应的string表⽰的数字减一DECRBY将key对应的string表⽰的数字加上对应的值
因为负数的存在,INCR和DECR可以通过负数相互替代
上面的运算都是针对整型的,因此会出现如下情况
key不存在- 先自动创建一个值为0的键值对,然后运行指令
key存在类型为整型:正常执行类型不为整型:报错
INCRBYFLOAT将key对应的string表⽰的浮点数加上对应的值
这条指令专门用于处理浮点型的数据,若类型不匹配,会报错
APPEND
如同其名称,字符串尾部追加新的字符串,若不存在,则会先自动创建字符串。
GETRANGE
获取key对应字符串的一段区间,特别的,这里是左闭右闭区间,可以用负数表示倒数,和Python的下标访问一样。超出的范围Redis会根据字符串的长度自动调整成合法的访问范围
1 | GETRANGE key start end |
SETRANGE
除了获取一段区间,也可以设置一段区间。不同于上面的GETRANGE,这里只需要给出起始偏移量即可(左闭)
如果起始偏移量前面没有初始值,Redis则会用空字符\x00自动填充,不存在的key也会自动创建和填充
1 | SETRANGE key offset value |
STRLEN
获取字符串的长度,若类型不匹配,则会报错
- 时间复杂度:O(1)
三种内部编码
int:8字节的长整型embstr: 小于等于39个字节的字符串raw:大于39个字节的字符串
关于embstr和raw的区别
| 维度 | embstr (embedded string) | raw (动态字符串) |
|---|---|---|
| 存储方式 | RedisObject与SDS连续存储 | RedisObject与SDS分离存储 |
| 内存分配 | 单次内存分配(连续空间) | 两次内存分配 |
| 最大长度 | ≤44字节(Redis5+) | >44字节 |
| 修改特性 | 只读(修改后自动转raw) | 可修改 |
Hash 哈希
| 数据结构 | 内部编码 |
| hash | hashtable |
| ziplist |
⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数组、映射
也就是说在原本的key-value_hash_table(hash类型)下,又嵌套了一层哈希表。这个value_hash_table内又存了一张哈希表提供键值对映射
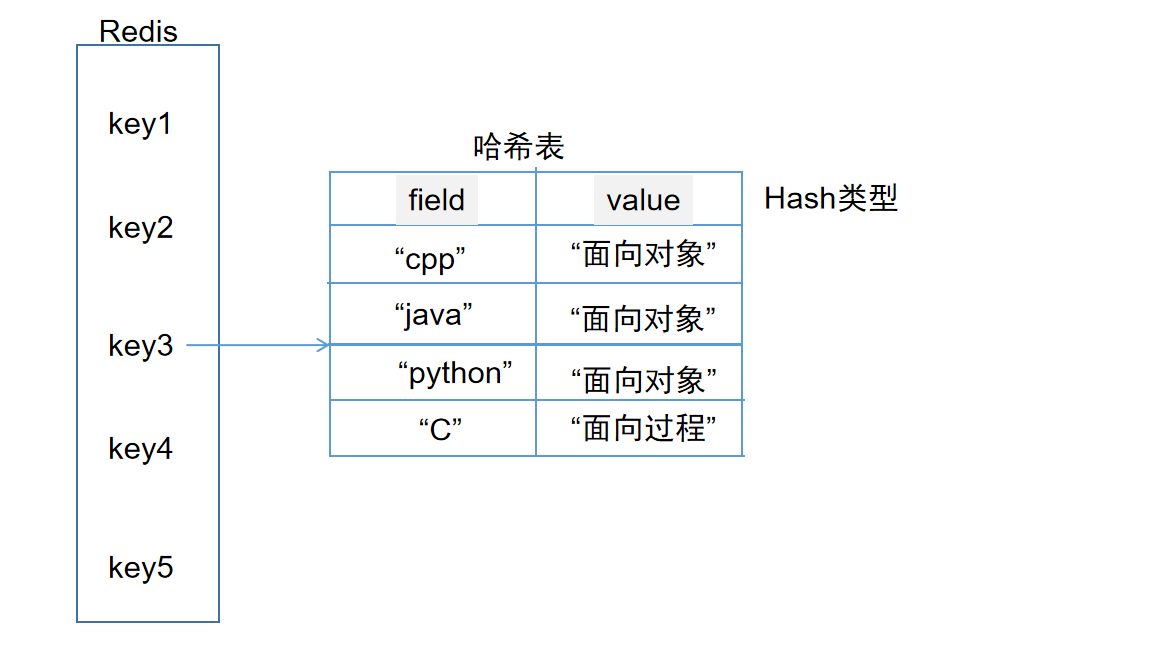
注:如上图,为了区分,key是指redis中的键,field是指哈希表中的键
接下来介绍相关指令
HSET
设置指定hash中指定字段field的值(value)
语法:
1 | HSET key field value [field value...] |
- 时间复杂度:O(N),N为字段数量
- 返回值:添加字段的数量
特别的,针对同一个key的HSET指令可以叠加,可以多次调用设置不同的域
HGET
获取hash中指定字段的值
1 | HGET key field |
HEXISTS
判断hash中是否有指定字段
1 | HEXISTS key field |
HDEL
删除哈希中的指定字段,可以删除多个
1 | HDEL key field [field ...] |
HKEYS
返回hash中所有的字段,返回值是一个字段列表
1 | HKEYS key |
HVALS
获取hash中的所有的值,返回值为值的列表
1 | HVALS key |
HGETALL
获取hash中的所有字段以及对应的值,返回值是域、值、域、值相间隔的列表
HMGET
一次获取多个字段的值
HLEN
获取hash中字段的个数
HSETNX
必定创建全新的字段,在字段不存在的情况下,设置hash中字段的值
HINCRBY
将hash中字段对应的数值添加指定的值
HINCRBYFLOAT
上面指令的浮点数版本
内部编码
哈希的内部编码有两种:
ziplist:压缩双向列表,ziplist使用更加紧凑的控件结构实现多个元素的内存上连续存储,可以提高CPU缓存的命中率hashtable:哈希表,以牺牲空间的方式保证O(1)的读写效率
常见使用方式
哈希表可以用来简单地存储关系型数据库的数据表,但是对于存储关系型数据库中存在nil的列时可能会出现表示困难的问题,以及基本无法做到关系型数据库的复杂查询,例如联表查询,聚合查询等。
不过使用哈希表存储表结构有个数据内聚的优势
List列表
| 数据结构 | 内部编码 |
| list | linkedlist |
| ziplist |
列表类型⽤来有序地存储多个字符串,列表中的每个字符串称为元素(element),⼀个列表最多可以存储 $2^{32}$ -1 个元素。Redis中的列表为双向列表,两端均可高效的插入和弹出元素,也支持下标访问,但是效率较低
指令表格如下:
| 指令名称 | 指令功能 |
|---|---|
| LPUSH | 将一个或多个元素从左侧插入 |
| LPUSHX | key存在时,执行LPUSH的功能 |
| RPUSH | 将一个或多个元素从右侧插入 |
| RPUSHX | key存在时,执行RPUSH的功能 |
| LRANGE | 获取start到end区间的所有元素,左闭右闭区间 |
| LPOP | 从list左侧取出并返回元素 |
| RPOP | 从list右侧取出并返回元素 |
| BLPOP | LPOP的阻塞版本,当List为空时会根据timeout阻塞等待一段时间,客户端会被阻塞,但Redis可以先去处理其它命令 |
| BLPOP | RPOP的阻塞版本,当List为空时会根据timeout阻塞等待一段时间,客户端会被阻塞,但Redis可以先去处理其它命令 |
| LINDEX | 获取指定下标的元素,O(N)效率(L指的是list) |
| LINSERT | 在特定下标插入元素,O(N)效率(L指的是list) |
| LLEN | 获取List的长度 |
内部编码:
ziplist:压缩双向列表,ziplist使用更加紧凑的控件结构实现多个元素的内存上连续存储,可以提高CPU缓存的命中率linkedlist:内存上离散的普通的双向链表
常见使用场景
消息队列
因为Redis是单线程模型,天然的没有同步互斥问题,可以直接使用LPUSH和BRPOP明显实现消息队列分频道的消息队列
通过使用不同的key指向不同的list,就可以实现模拟不同的频道进行消息队列的传递。
Set集合
| 数据结构 | 内部编码 |
| set | hashtable |
| intset | |
集合类型用于不重复地存储多个字符串类型的元素。⼀个集合最多可以存储 $2^{32}$ -1 个元素,Redis除了⽀持集合内的增删查改操作,同时还⽀持多个集合取交集、并集、差集的集合运算
指令表格如下:
| 指令名称 | 指令功能 |
|---|---|
| SADD | 将一个或多个元素添加到集合中 |
| SMEMBERS | 获取一个SET中的所有元素,尽管集合本身是无序的 |
| SISMEMBER | 判断一个元素在不在set中 |
| SCARD | 获取集合中的元素个数 |
| SPOP | 随机删除并取出一个或多个(可选项)元素 |
| SMOVE | 将一个指定元素从源set移动到目的set |
| SREM | 将一个或多个指定元素从set中删除 |
| SINTER | 将一个或多个指定集合取交集 |
| SINTERSTORE | 将一个或多个指定集合取交集,并把结果存入参数中的第一个set中,注:目的set中原本的内容会被丢弃 |
| SUNION | 将一个或多个指定的集合取并集 |
| SUNIONSTORE | 将一个或多个指定集合取并集,并把结果存入参数中的第一个set中,注:目的set中原本的内容会被丢弃 |
| SDIFF | 将一个或多个指定的集合取差集 |
| SDIFFSTORE | 将一个或多个指定集合取差集,并把结果存入参数中的第一个set中,注:目的set中原本的内容会被丢弃 |
内部编码有两种:
intset: 整数集合。当且仅当集合中的元素全都是整型且元素个数较小时,Redis会使用intset来实现hashtable: 普通的哈希表
常见使用场景
集合类型比较典型的使用场景就是标签(tag)。可以给标签添加用户,也可以给用户添加标签
Zset有序集合
| 数据结构 | 内部编码 |
| zset | skiplist |
| ziplist |
有序集合相比于集合,每个元素都多了一个唯一的浮点类型的分数与之关联,Zset依赖于这个分数维护几何元素的有序性
不过尽管元素不能重复,分数是允许重复的。
指令表格如下:
| 指令名称 | 指令功能 |
|---|---|
| ZADD | 添加或更新指定元素即关联的分数到zset中,支持 +inf/-inf ,时间复杂度log(N) |
| ZCARD | 返回zset的元素个数 |
| ZCOUNT | 返回分数在[min,max]区间内的元素个数,可以添加()变为开区间 |
| ZRANGE | 返回指定下标区间内的元素,按分数升序。带上WITHSCORES参数可以把分数也返回 |
| ZREVRANGE | 返回指定下标区间内的元素,按分数降序 |
| ZRANGEBYSCORE | 返回分数在区间内的元素。 |
| ZPOPMAX | 删除并返回分数最高的一个或多个元素 |
| BZPOPMAX | ZPOPMAX的阻塞版本 |
| ZPOPMIN | 删除并返回分数最低的一个或多个元素 |
| BZPOPMIN | ZPOPMIN的阻塞版本 |
| ZRANK | 返回指定元素的分数升序排名下标 |
| ZREVRANK | 返回指定元素的分数降序排名下标 |
| ZSCORE | 返回指定元素的分数 |
| ZREM | 删除指定的元素 |
| ZRemRangeByRank | 按照分数升序删除指定下标范围内的元素,左闭右闭 |
| ZRenRangeByScore | 按分数区间删除指定分数范围内的元素 |
| ZINCRBY | 为指定元素的关联分数添加指定的分数值 |
集合运算指令
因为Zset的集合运算指令比较复杂,就拿出来单独介绍了
聚合方式:
- 我们首先介绍聚合方式
AGGREGATE选项,它有如下三个选项SUM取所有目标的分数代数和,可以变种为SUM with weight,带权求和MAX取所有目标的最大分数MIN取所有目标的最小分数
如图: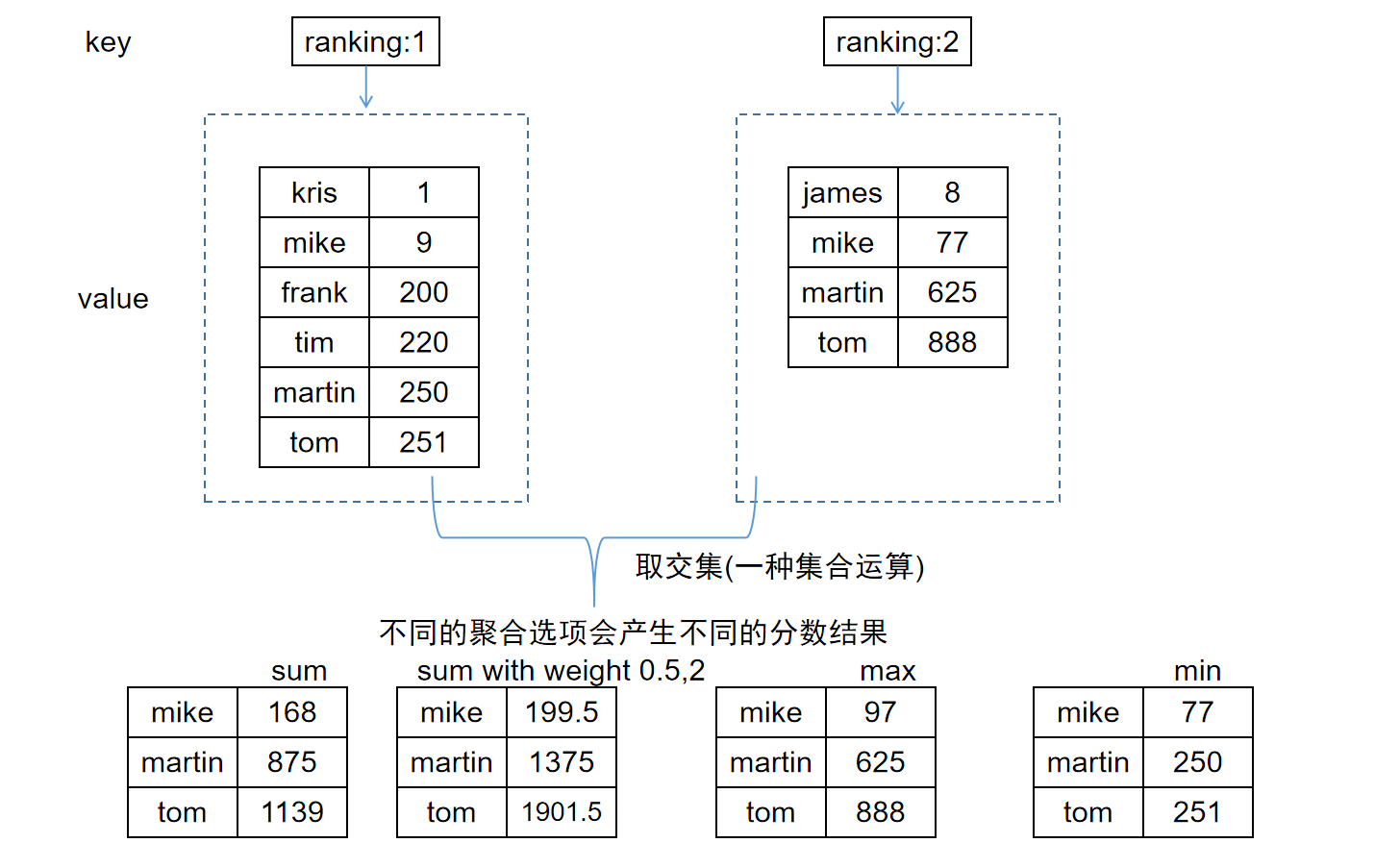
- ZINTERSTORE
交集操作,求给定有序集合的交集并存入进目标有序集合中
语法:
1 | ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight |
- ZUNIONSTORE
并集操作,求给定有序集合的并集并存入进目标有序集合中
语法:
1 | ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight |
内部编码
有序集合主要有两种编码方式
ziplist:压缩列表,数据较少时使用压缩链表,一方面提高内存利用率,另一方面提高CPU缓存命中率skiplist:跳表,一种查询效率达log(N)的数据结构,用于存储更大的有序集合
初阶结尾
至此对于Redis的初阶的认识已经完成,接下来我们会在别的博客中完成C++ Redis客户端的认识、Redis持久化机制和Redis主从复制、哨兵模式等机制的探究。