背景分析 背景概述 在当今快速发展的金融市场中,股票市场的动态变化对投资者和金融分析师至关重要。随着信息技术的进步,特别是互联网和大数据技术的发展,投资者可以实时获得大量的股票市场信息。然而,这些信息通常以原始数据形式存在,需要进一步处理和分析才能提取有价值的洞见。在这种背景下,网络股票信息爬虫与可视化技术应运而生,成为股票市场分析的重要工具。
网络股票信息爬虫 网络股票信息爬虫(Web Scraping)是一种自动化的数据收集技术,旨在从互联网上提取股票市场相关的信息。它利用程序化方法访问和抓取各种金融网站和新闻平台上的数据,例如股票价格、交易量、公司财报、新闻动态等。爬虫技术可以高效地从大规模数据源中获取最新的信息,支持实时数据更新和历史数据回溯分析。
关键技术 :
爬虫框架:如Scrapy、BeautifulSoup等,用于解析HTML页面和提取数据。
由于本文的目标网站的股票数据并不在页面中,也就是说不需要做网页分析和提取
API接口:一些金融网站提供API接口,允许程序直接获取结构化的数据。
(例如本文使用Get方法的https请求,获取了json文件)
数据存储:抓取的数据通常需要存储在数据库中,如MySQL、MongoDB等,以便后续分析和处理。
(本文使用作者个人服务器上MYSQL作为存储数据库)
数据可视化 数据可视化是将复杂的股票市场数据以图形化的方式呈现出来,使得数据更易于理解和分析。通过可视化技术,投资者可以直观地观察股票价格趋势、交易量变化、市场波动等重要信息,从而做出更加明智的投资决策。
常用可视化方法 :
时间序列图:示股票价格或交易量随时间变化的趋势。
蜡烛图(CandlestickChart):用于股票价格在一定时间内的开盘、收盘、最高和最低价格。
热力图(Heatmap):用颜色强度表示不同股票的表现或市场的热点区域。
散点图和折线图:用于展示多维数据之间的关系和趋势。
小结 网络股票信息爬虫与可视化技术在金融市场分析中具有广泛的应用。它们不仅可以帮助投资者实时监控市场动态,还能够通过历史数据分析预测未来趋势。此外,这些技术还被用于量化分析、算法交易、风险管理等领域,以提高投资决策的科学性和准确性。
网络股票信息爬虫与可视化技术为现代金融市场提供了强大的数据支持和分析工具。通过自动化数据抓取和图形化呈现,投资者可以更高效地获取市场信息和洞察,有助于做出更准确的投资决策。随着技术的不断发展,这些工具将在金融分析中发挥越来越重要的作用。
业务流程图
代码实现业务功能 代码框架
网络爬虫
使用requests模块向网站发送定制的https请求
使用json处理网站返回的json数据
爬虫部分的代码封装在SnowBallCrawler.py中
数据库持久化
在mysql中创建项目所需的数据库和表
使用pymysql模块连接数据库并执行插入和查询操作
GUI可视化
使用dearpygui模块实现GUI可视化并管理组件
使用dearpygui的统计图绘制功能绘制K图
项目的主要逻辑集成在可视化代码的主要部分
将自定义的复杂组件封装在类里
网络爬虫 我们首先来实现网络爬虫部分,这里的目标网站是雪球网站的茅台股票
网页分析 一般股票网站的数据不会直接放在原始的https请求的响应中,所以要打开F12分析网站的二次请求的内容,方法有两种:
方法一如图 :
按下f12打开网页分析器
点击选项卡中的网络(Network)切换到对应的页面,并选中下方的Fetch/XHR分类卡
刷新网页,并点击网站中的日K选项,鼠标悬停在某一天的线上
从悬停提示的数字中选一个比较有唯一性的(比如收盘价),在搜索中填入选中的数字
一般这样就能选出唯一的响应了,里面就存着我们所需要的数据(我们这个例子就有280多条数据)
方法二
如果方法一搜索不出来,还可以使用限定抓包时间的方法,减小搜索范围
按下f12打开网页分析器
点击选项卡中的网络(Network)切换到对应的页面,并选中下方的Fetch/XHR分类卡
刷新网页,等待网页完全加载后,再来回切换日K和周K(或其它类似选项卡),观察时间轴窗口的变化
最后点击日K选项卡,在时间轴窗口单击发生变化的地方,然后调整观察区间
搜索筛选出来的响应
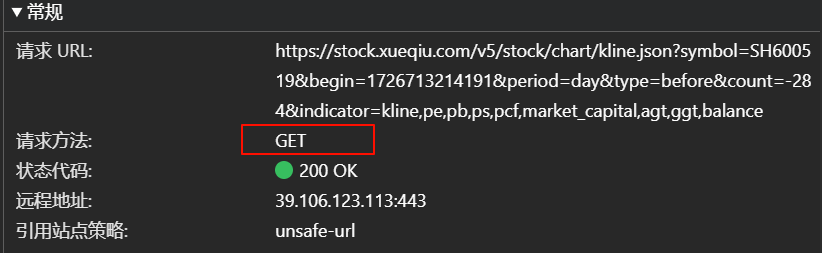
如图,我们找到了想要的响应,接下来我们分析标头header,接下来点击标头选项卡
如图,目标网站使用了GET方法请求数据,所以我们要着重分析GET方法的参数和无参URL(用于拼接请求URL),而参数就在URL中
拆分参数并转换成python字典后如下
1 2 3 4 5 6 7 8 param_data = { 'symbol' :'SH600519' , 'begin' :1726713214191 , 'period' :'day' , 'type' :'before' , 'count' :'-284' , 'indicator' :'kline,pe,pb,ps,pcf,market_capital,agt,ggt,balance' }
很明显,begin是时间戳,用于请求最新的数据,但是比较特别的,网站用的是整数的毫秒级时间戳,在python中使用time模块传当前的begin值时得注意
因为本项目只爬取一支股票的信息,剩下的参数不作解析
为了防止被网站的反爬取给拦截下来,标头需要和自己在网站里查到的保持一致
转成python字典的代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 self .headers = { 'Accept' :'application/json, text/plain, */*' , 'Accept-Encoding' :'gzip, deflate, br, zstd' , 'Accept-Language' :'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' , 'Cookie' :'请使用自己的Cookie,本文作者已隐去' , 'Origin' :'https://xueqiu.com' , 'Priority' :'u=1, i' , 'Referer' :'https://xueqiu.com/S/SH600519' , 'Sec-Ch-Ua' :'"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"' , 'sec-ch-ua-mobile' :'?0' , 'sec-ch-ua-platform' :'"Windows"' , 'Sec-Fetch-Dest' :'empty' , 'Sec-Fetch-Mode' :'cors' , 'Sec-Fetch-Site' :'same-site' , 'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0' }
封装类 因为只爬取一支股票,就不封装通用性强的类了,而是只针对这一支股票,所以封装一个GZMaoTai类,并提供get_response接口,向外界传送每次爬取的数据。其中对返回的joson格式的字符串,使用Josn模块将其反序列化,并储存在Python列表中返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import requestsimport jsonimport timeclass GZMaoTai : def __init__ (self ): self .url = 'https://stock.xueqiu.com/v5/stock/chart/kline.json' self .headers = { 'Accept' :'application/json, text/plain, */*' , 'Accept-Encoding' :'gzip, deflate, br, zstd' , 'Accept-Language' :'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' , 'Cookie' :'请使用自己的Cookie,本文作者已隐去' , 'Origin' :'https://xueqiu.com' , 'Priority' :'u=1, i' , 'Referer' :'https://xueqiu.com/S/SH600519' , 'Sec-Ch-Ua' :'"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"' , 'sec-ch-ua-mobile' :'?0' , 'sec-ch-ua-platform' :'"Windows"' , 'Sec-Fetch-Dest' :'empty' , 'Sec-Fetch-Mode' :'cors' , 'Sec-Fetch-Site' :'same-site' , 'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0' } def get_response (self,date ): nowtime = int (time.time() * 1000.0 ) param_data = { 'symbol' :'SH600519' , 'begin' :str (nowtime), 'period' :'day' , 'type' :'before' , 'count' :'-284' , 'indicator' :'kline,pe,pb,ps,pcf,market_capital,agt,ggt,balance' } print ("开始爬取数据" ) response = requests.get(self .url,headers=self .headers,params=param_data,timeout=5 ) print (response.text) print ("爬取成功,数据包如上" ) data_json = json.loads(response.text) items = data_json['data' ]['item' ] return items
数据库持久化 数据库准备 这里使用远端的MYSQL管理数据库,作者使用了自己的服务器,具体的配置和安装不作介绍。
我们创建一个用于存储股票表的数据库stock
1 create database if not exists stock
我们针对本次实验,再创建一个MaoTai表。(若要自动建表,则这部分在代码实现)
1 2 3 4 5 6 7 8 9 10 11 12 create table MaoTai( timesamp bigint not null, volume int not null, open decimal(8,4) not null, high decimal(8,4) not null, low decimal(8,4) not null, close decimal(8,4) not null, chg decimal(8,4) not null, percent decimal(8,4) not null, turnoverrate decimal(8,4) not null, amount decimal(12,1) not null );
特别说明地,这边的timesamp是拼写错误😅,这个表结构不是特别好看,也没有设置主键,亲身实践,时间戳太大了,不能作为主键,否则这个表的增删查改会超时
我们创建一个专门管理股票数据库的远程登录账户supdiver,并把用户权限限定在stock.MaoTai表上
Mysql8.0语法
1 2 3 create user supdriver@% identified by '密码'; grant all privileges on stock.MaoTai to supdriver@%
代码封装 对于数据库的操作主要是封装几个接口,所以就直接把有关的函数声明在DBManager.py模块中,而不封装成类了。
主要操作就是连接到数据库,然后创建cursor指针用于执行mysql语句并获取返回值
注:host为mysql所在服务器的公有ip,本文将作者自己服务器的实际ip改成了本地路由环回的127.0.0.1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import pymysqlstockDB = pymysql.Connect( host='47.99.48.121' , port=3306 , user='supdriver' , password='' , db='stock' , charset='utf8' , autocommit=True ) def sendData (items ): stockDB.ping(reconnect=True ) cursor = stockDB.cursor() print ("开始向数据库插入数据" ) for item in items: sql=(f"insert into MaoTai values ({item[0 ]} ," f"{item[1 ]} ," f"{item[2 ]} ," f"{item[3 ]} ," f"{item[4 ]} ," f"{item[5 ]} ," f"{item[6 ]} ," f"{item[7 ]} ," f"{item[8 ]} ," f"{item[9 ]} );" ) cursor.execute(sql) print (f"插入数据成功,总计{len (items)} " ) def getAllData (stockDB ): stockDB.ping(reconnect=True ) cursor = stockDB.cursor() sql= "select * from MaoTai" cursor.execute(sql) return cursor.fetchall() def getLatestData (): stockDB.ping(reconnect=True ) cursor=stockDB.cursor() sql="select * from MaoTai order by timesamp desc" cursor.execute(sql) alldata = cursor.fetchall() resList = [] for line in alldata: resList.append(line) return resList def closeDB (): stockDB.close() def clearDB (): stockDB.ping(reconnect=True ) cursor = stockDB.cursor() sql='delete from MaoTai' print ("开始清理数据库" ) cursor.execute(sql) print ('清理完成' )
GUI可视化和K图绘制 接下来就是整个项目的重头戏,经过前面的封装,数据的获取,储存和预处理已经完成
我们这里使用的可视化模块叫做dearpygui ,后面简称dpg
关于可视化组件的上下文,将交由dearpygui自动为维护,这里对dpg不多作介绍,先介绍最重要的一个概念:dpg中所有的组件都有自己的uuid用于维护,因此对组件的管理就是对组件id的管理,其中id既可以是整型也可以是字符串
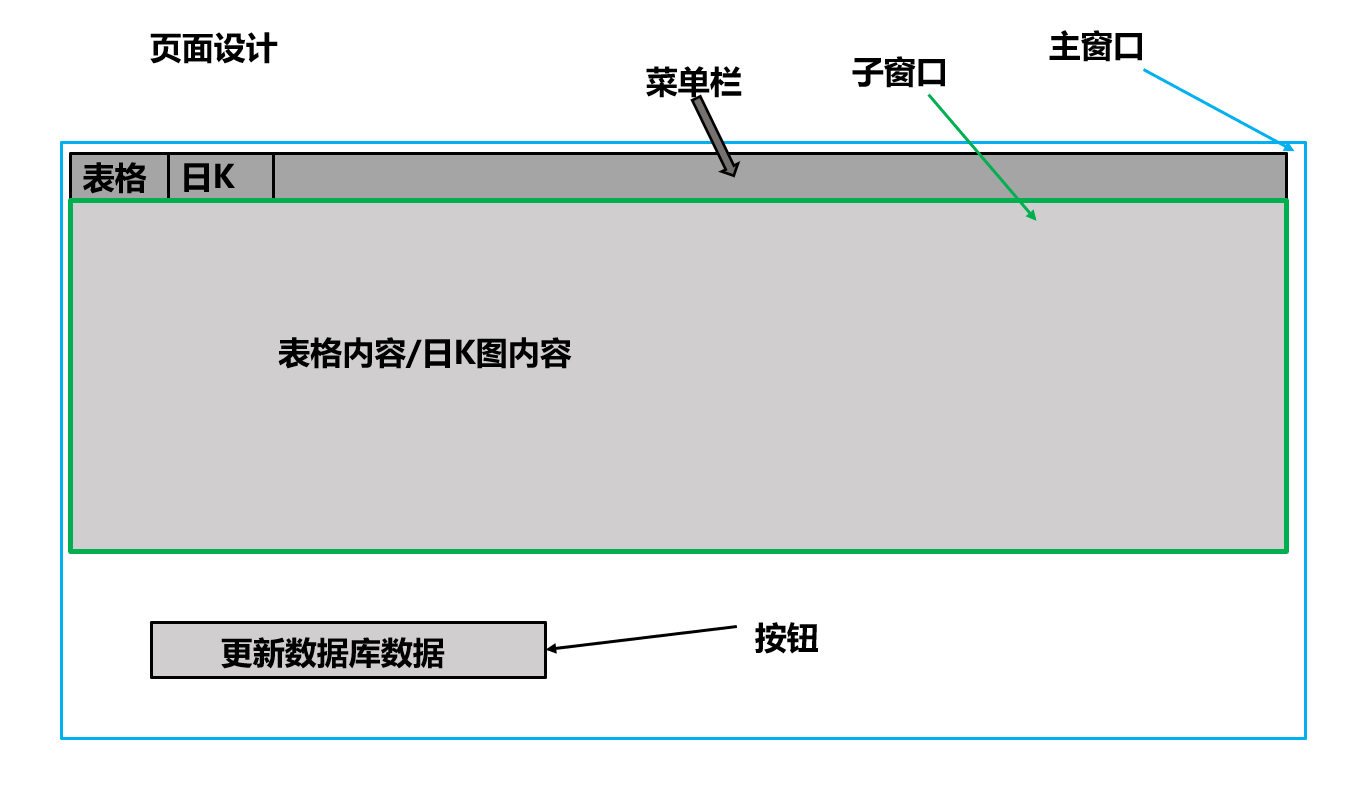
页面设计 做工程要有蓝图,做可视化当然要有页面设计来指导代码实现,否则想到哪做到哪会十分缺乏效率。我们预期的页面设计如下
封装主窗口类并显示 所有的dpg的可视化组件需要创建在dpg的上下文中,所以要封装类,就得使用其提供的dpg.stage()来在类里创建临时上下文
DVWrapper.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import timeimport dearpygui.dearpygui as dpgfrom SnowBallCrawler import *class Window : def __init__ (self,label,tag ): with dpg.stage() as stage: self .id = dpg.add_window(label=label,tag=tag) self .stage = stage def add_child (self,child ): dpg.move_item(child.id ,parent=self .id ) def add_childID (self,childID ): dpg.move_item(childID,parent=self .id ) def submit (self ): dpg.unstage(self .stage)
在DVWrapper.py中封装好Window类后,我们在DataVisual.py中创建dpg的上下文并将Window类实例化出来
DataVisual.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from DVWrapper import *import DBManager as dbmimport timedpg.create_context() main_win = Window(label="main_win" ,tag="main_win" ) main_win.submit() dpg.create_viewport(title='Custom Title' , width=1400 , height=600 ) dpg.setup_dearpygui() dpg.show_viewport() dpg.set_primary_window("main_win" , True ) dpg.start_dearpygui() dpg.destroy_context()
封装子窗口类 光有主窗口还不够,还需要子窗口来限制未来要展示的表格,防止表格过长,占用主窗口过多的空间
DVWrapper.py
1 2 3 4 5 6 class Child_Window : def __init__ (self,width=1200 ,height=300 ,tag=TOP_CHILD_WINDOW ): with dpg.stage(): self .id = dpg.add_child_window(tag=tag,width=width,height=height) def add_child (self,child ): dpg.move_item(child.id ,parent=self .id )
封装Table类 我们封装一个Table类来执行更新表格和显示表格的功能
DVWrapper.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 def mystampToNumStr (stamp ): date = time.strftime("%Y/%m/%d" , time.localtime(int (stamp / 1000.0 ))) return date TOP_CHILD_WINDOW = "top_child_win" columns = ['序号' ,'时间' ,'成交量(手)' ,'开盘价' ,'最高价' ,'最低价' ,'收盘价' ,'涨跌额' ,'涨跌幅' ,'换手率' ,'成交额(亿)' ] class DataTable : def __init__ (self,tag='main table' ): with dpg.stage(): self .id = dpg.add_table(header_row=True , policy=dpg.mvTable_SizingFixedFit, row_background=True , reorderable=True , resizable=True , no_host_extendX=False , hideable=True , borders_innerV=True , delay_search=True , borders_outerV=True , borders_innerH=True , borders_outerH=True ,tag=tag) dpg.push_container_stack(self .id ) for i in range (len (columns)): dpg.add_table_column(label=columns[i],width_stretch=True , init_width_or_weight=0.0 ) dpg.pop_container_stack() def clearData (self ): for item in dpg.get_item_children(self .id ,1 ): dpg.delete_item(item) def updateData (self,items ): dpg.push_container_stack(self .id ) row = 0 for item in items: row+=1 with dpg.table_row(): dpg.add_text(str (row)) for j in range (len (item)): if (j == 0 ): date = mystampToNumStr(item[0 ]) dpg.add_text(date) elif (j==10 ): break else : dpg.add_text(item[j]) dpg.pop_container_stack()
封装KPlot类 KPlot对外只负责接受数据和绘制统计图,而内部的工作有:
DVWrapper.py
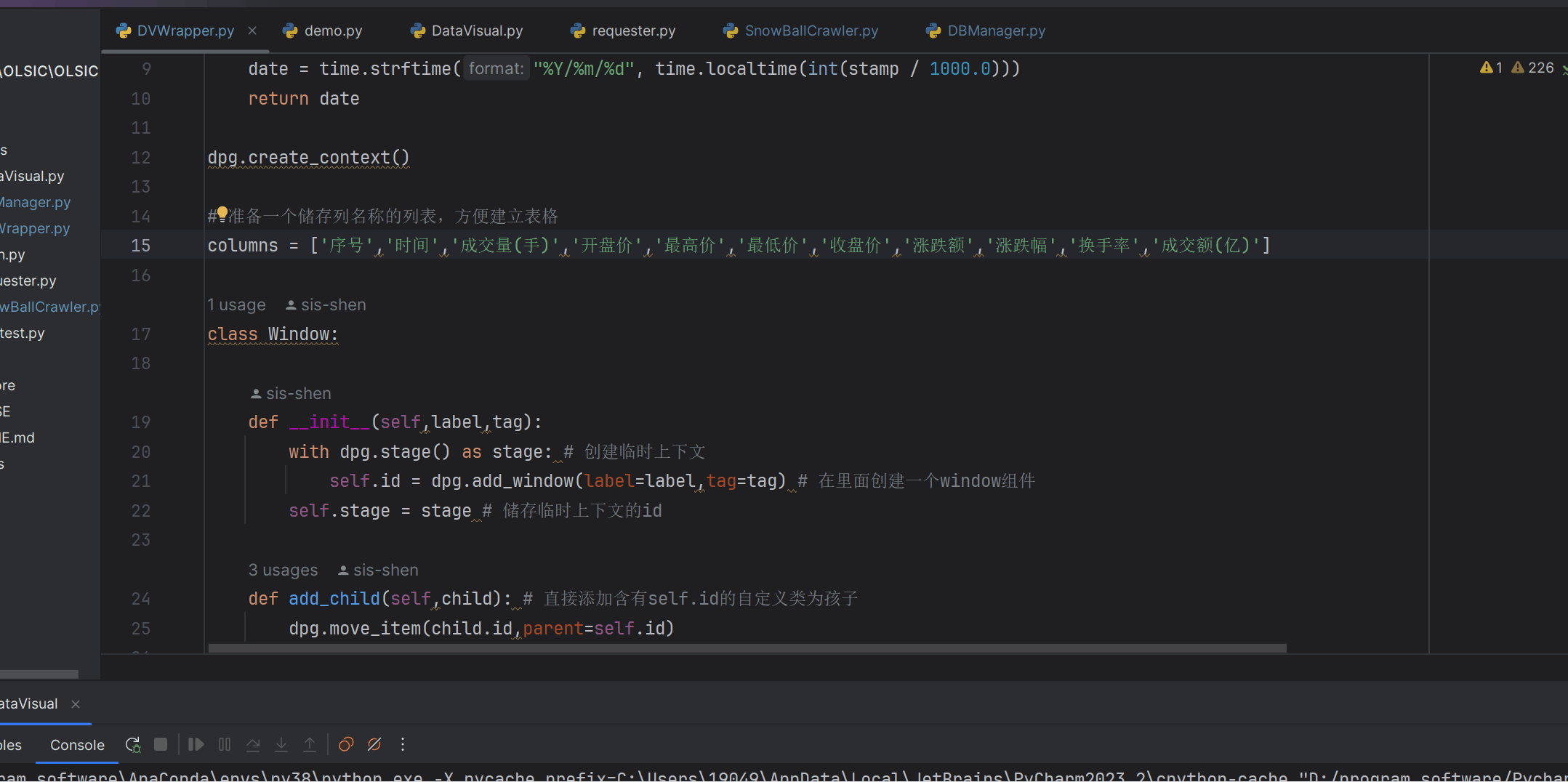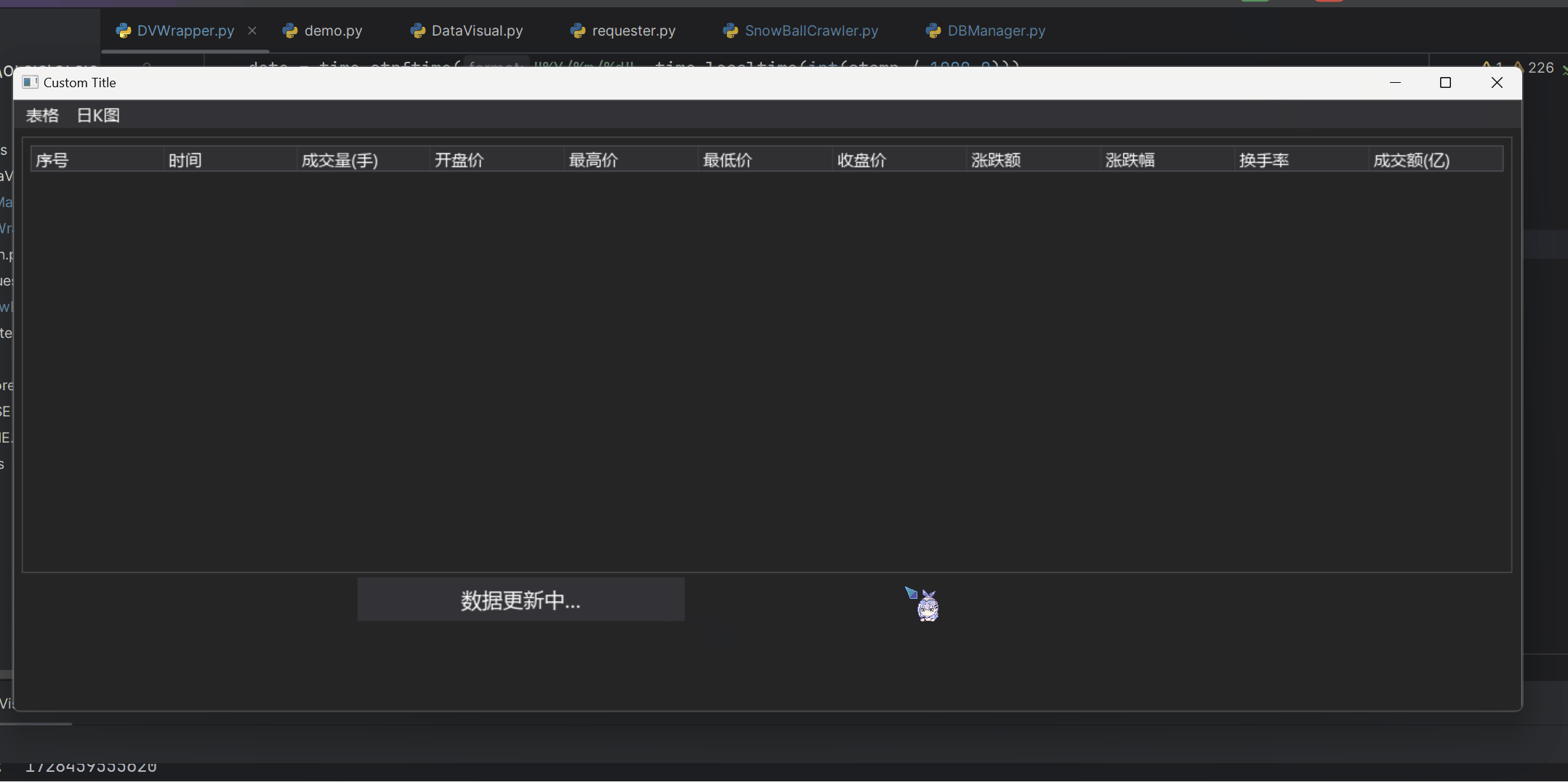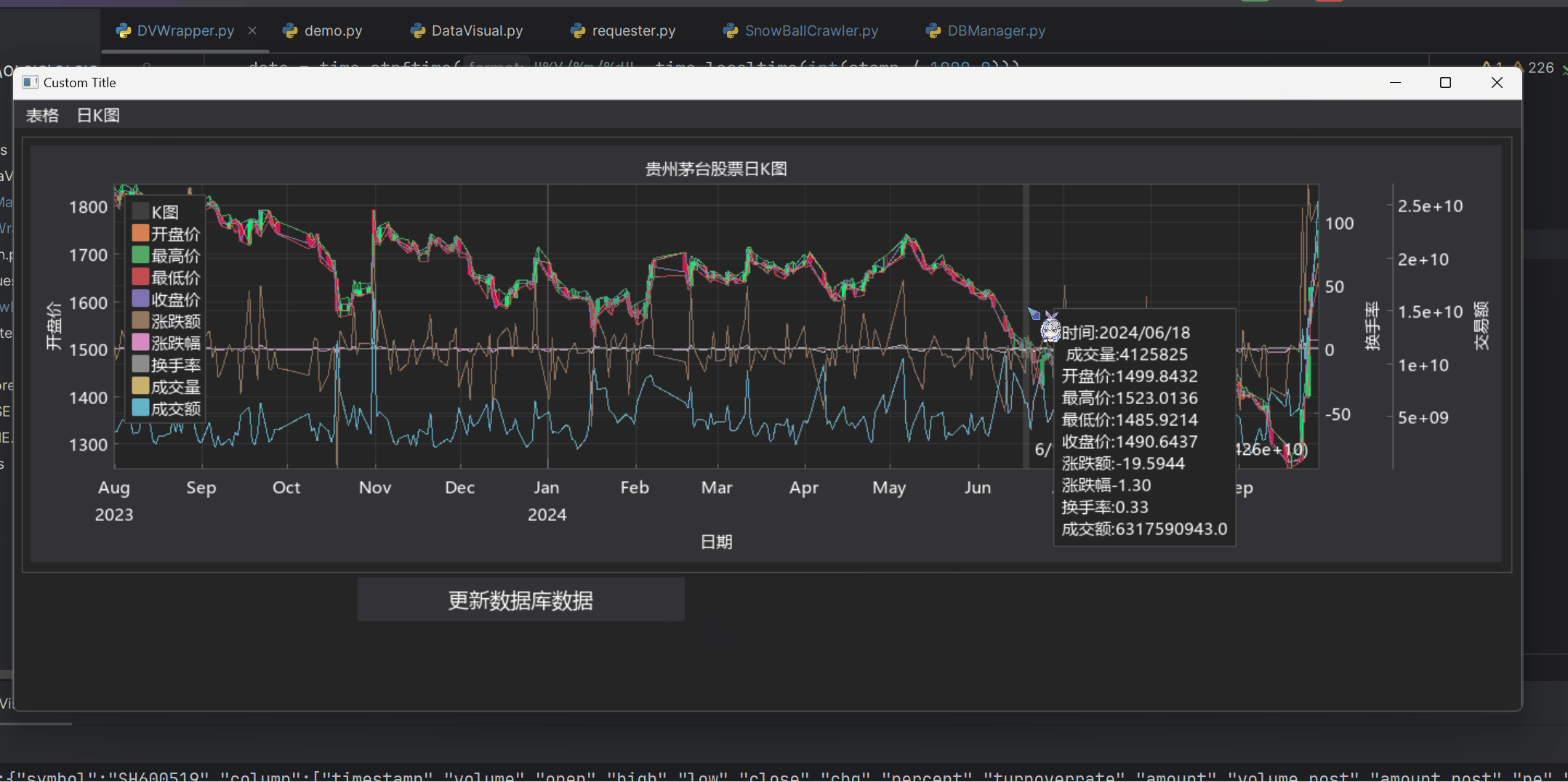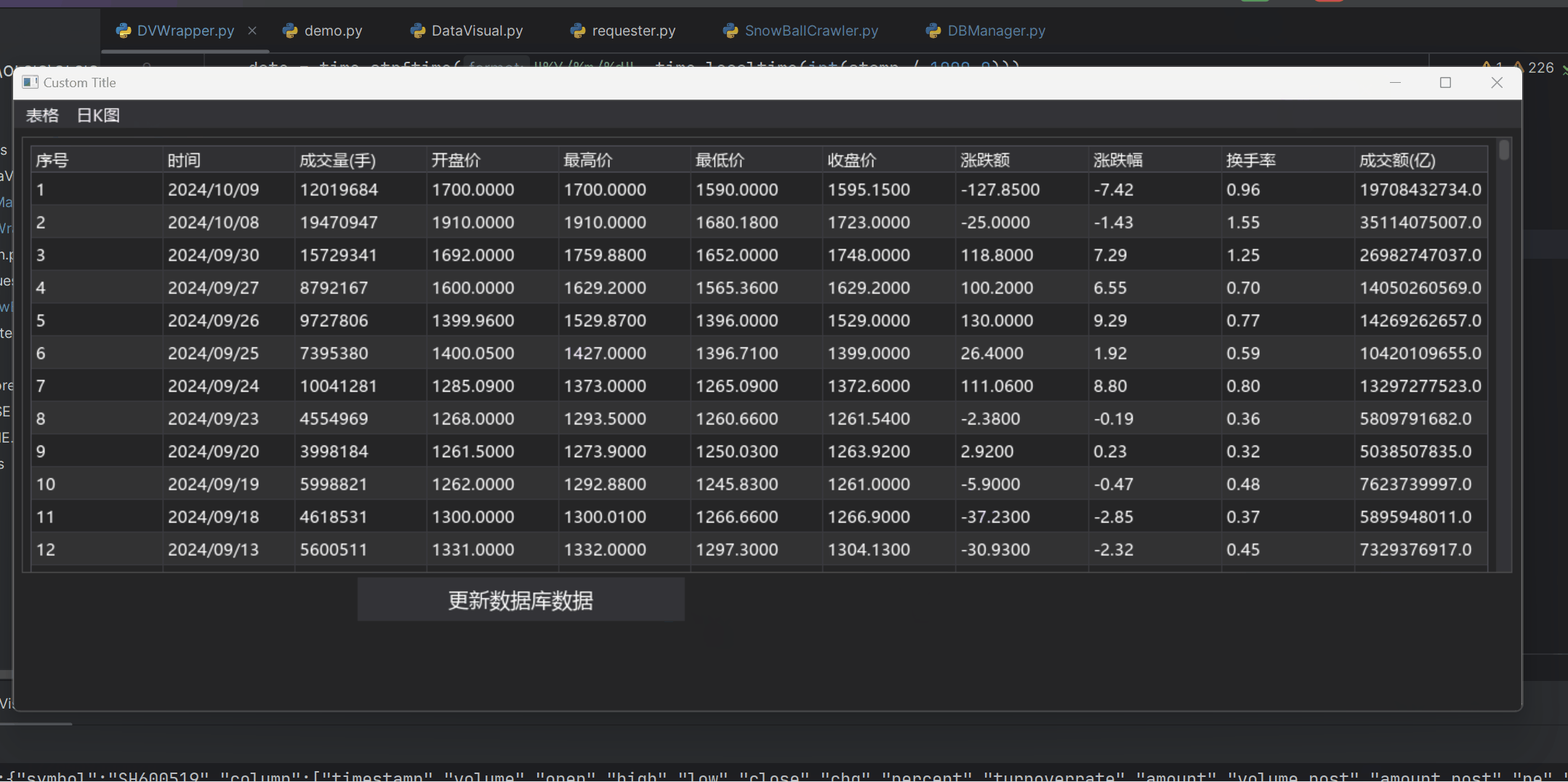
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 class KPlot : def __init__ (self ): with dpg.stage(): with dpg.plot(label="贵州茅台股票日K图" ,tag='kplot' ,height=-1 ,width=-1 ,show=False ) as self .id : dpg.add_plot_legend() def draw (self,fetch_data ): xData=[] yDatas={"volume" :[],"open" :[],"high" :[],"low" :[], "close" :[],"chg" :[],"percent" :[], "turnoverrate" :[],"amount" :[]} for line in fetch_data: line = list (line) xData.append(line.pop(0 )/1000 ) yDatas["volume" ].append(line.pop(0 )) yDatas["open" ].append(line.pop(0 )) yDatas["high" ].append(line.pop(0 )) yDatas["low" ].append(line.pop(0 )) yDatas['close' ].append(line.pop(0 )) yDatas['chg' ].append(line.pop(0 )) yDatas['percent' ].append(line.pop(0 )) yDatas['turnoverrate' ].append(line.pop(0 )) yDatas['amount' ].append(line.pop(0 )) def custom_tooltip_handler (sender,app_data ): x_data,y_data=dpg.get_plot_mouse_pos() date = mystampToNumStr(x_data*1000 ) index = 0 while ( index < len (xData) and date != mystampToNumStr(xData[index]*1000 ) ): index+=1 if (index < len (xData)): dpg.set_value("volume tip" ,f"时间:{date} \n " f"成交量:{yDatas['volume' ][index]} \n" f"开盘价:{yDatas['open' ][index]} \n" f"最高价:{yDatas['high' ][index]} \n" f"最低价:{yDatas['low' ][index]} \n" f"收盘价:{yDatas['close' ][index]} \n" f"涨跌额:{yDatas['chg' ][index]} \n" f"涨跌幅{yDatas['percent' ][index]} \n" f"换手率:{yDatas['turnoverrate' ][index]} \n" f"成交额:{yDatas['amount' ][index]} " ) with dpg.handler_registry(tag="volume hander" ): dpg.add_mouse_move_handler(callback=custom_tooltip_handler) dpg.push_container_stack(self .id ) xaxis = dpg.add_plot_axis(dpg.mvXAxis,label="日期" ,time=True ) dpg.add_plot_axis(dpg.mvYAxis,label='开盘价' ,tag="open" ) dpg.add_plot_axis(dpg.mvYAxis,label='换手率' ,tag="turnoverrate" ) dpg.add_plot_axis(dpg.mvYAxis,label='交易额' ,tag="amount" ) dpg.add_line_series(xData,yDatas["volume" ],parent="amount" ,label="成交量" ) s1id = dpg.add_candle_series(xData,opens=yDatas['open' ],closes=yDatas['close' ],lows=yDatas['low' ],highs=yDatas['high' ],parent='open' ,label='K图' ,time_unit=dpg.mvTimeUnit_Day) dpg.add_line_series(xData,yDatas["open" ],parent='open' ,label="开盘价" ) dpg.add_line_series(xData,yDatas["high" ],parent='open' ,label="最高价" ) dpg.add_line_series(xData,yDatas["low" ],parent='open' ,label='最低价' ) dpg.add_line_series(xData,yDatas["close" ],parent='open' ,label='收盘价' ) dpg.add_line_series(xData,yDatas["chg" ],parent='turnoverrate' ,label='涨跌额' ) dpg.add_line_series(xData,yDatas["percent" ],parent='turnoverrate' ,label='涨跌幅' ) dpg.add_line_series(xData,yDatas["turnoverrate" ],parent='turnoverrate' ,label='换手率' ) dpg.add_line_series(xData,yDatas["amount" ],parent='amount' ,label='成交额' ) dpg.fit_axis_data(xaxis) with dpg.tooltip(s1id,label='tool tip' ,tag="tool tip" ): dpg.add_text("Hover the plot" ,tag="volume tip" ) dpg.pop_container_stack()
dpg的menu_bar组件就只是单纯的菜单栏,内部是空的,所以得先封装MenuItem类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class MenuItem (): def __init__ (self,menubar,label,tag,target ): self .parent = menubar.id self .target = target dpg.push_container_stack(self .parent) self .id = dpg.add_menu_item(label=label,tag=tag,user_data=[menubar,self ]) dpg.pop_container_stack() def HideCallback (self ): current_visible = dpg.is_item_visible(self .target) if current_visible: dpg.hide_item(self .target) def setCallback (self,callback ): dpg.set_item_callback(self .id ,callback=callback) class MenuBar (): def __init__ (self,tag='main menu' ): self .children = [] with dpg.stage(): self .id = dpg.add_menu_bar(tag=tag) def add_item (self,label,tag,target,font ): self .children.append(MenuItem(self ,label=label,tag=tag,target=target)) child_id = self .children[-1 ].id dpg.bind_item_font(child_id,font) self .children[-1 ].HideCallback() return child_id def hide_children (self ): for child in self .children: child.HideCallback()
封装水平按钮组 虽然目前只有一个按钮,但是为了方便以后在同一行放更多的按钮,我们选择再额外封装一个Group
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class HorGroup : def __init__ (self,width=40 ): with dpg.stage(): self .id = dpg.add_group(horizontal=True ,width=width) def add_child (self,child ): dpg.move_item(child.id ,parent=self .id ) def add_spacer (self ): dpg.push_container_stack(self .id ) dpg.add_spacer() dpg.pop_container_stack() class Button : def __init__ (self,label,tag ): with dpg.stage(): self .id =dpg.add_button(label=label,tag=tag,width=150 ,height=40 ) def setcallback (self,callback ): dpg.set_item_callback(self .id ,callback=callback)
类实例化和构建可视化页面 特别的,由于dpg默认不支持中文字体,所以要在项目里准备一个支持中文自己的文件,并在程序中使用该字体,才能正常显示中文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 import dearpygui.dearpygui as dpgfrom DVWrapper import *import DBManager as dbmimport timemaotai = GZMaoTai() def getTimestamp (): t=time.time() return int (round (t*1000 )) dpg.create_context() def commonMenuCallback (sender,app_data,user_data ): user_data[0 ].hide_children() dpg.show_item(user_data[1 ].target) def DBUpdateCallback (sender,app_data ): dpg.set_item_label(sender,"数据更新中..." ) dpg.disable_item(sender) dbm.clearDB() my_table.clearData() items = maotai.get_response(getTimestamp()) dbm.sendData(items) fetch_data = dbm.getLatestData() my_table.updateData(fetch_data) dpg.set_item_label(sender,"更新数据库数据" ) dpg.enable_item((sender)) with dpg.font_registry(): with dpg.font("./fonts/msyh.ttc" ,20 ) as default_font: dpg.add_font_range_hint(dpg.mvFontRangeHint_Chinese_Simplified_Common) with dpg.font("./fonts/msyh.ttc" ,25 ) as big_font: dpg.add_font_range_hint(dpg.mvFontRangeHint_Chinese_Simplified_Common) with dpg.font("./fonts/msyh.ttc" ,20 ) as menufont: dpg.add_font_range_hint(dpg.mvFontRangeHint_Chinese_Simplified_Common) my_table = DataTable() update_button = Button(label="更新数据库数据" ,tag="update button" ) update_button.setcallback(DBUpdateCallback) kplot = KPlot() menubar = MenuBar() table_menu = menubar.add_item(label="表格" ,tag="table" ,target=my_table.id ,font=menufont) kplot_menu = menubar.add_item(label="日K图" ,tag="Kplot" ,target=kplot.id ,font=menufont) dpg.set_item_callback(table_menu,commonMenuCallback) dpg.set_item_callback(kplot_menu,commonMenuCallback) main_win = Window(label="main_win" ,tag="main_win" ) top_child_win = Child_Window(width=-1 ,height=400 ) top_child_win.add_child(my_table) top_child_win.add_child(kplot) dpg.bind_font(default_font) dpg.bind_item_font(update_button.id ,big_font) dpg.bind_item_font(menubar.id ,menufont) main_win.add_child(menubar) main_win.add_child(top_child_win) button_group = HorGroup(width=300 ) button_group.add_spacer() inner_group = HorGroup() inner_group.add_child(update_button) button_group.add_child(inner_group) button_group.add_spacer() main_win.add_child(button_group) main_win.submit() fetch_data = dbm.getLatestData() my_table.updateData(fetch_data) kplot.draw(fetch_data) dbm.closeDB() dpg.create_viewport(title='Custom Title' , width=1400 , height=600 ) dpg.setup_dearpygui() dpg.show_viewport() dpg.set_primary_window("main_win" , True ) dpg.start_dearpygui() dpg.destroy_context()
成品展示 (文件较大,请耐心等待加载)
小结 在本次项目中,我们使用了互联网爬虫技术和可视化技术完成了项目目标,能够方便地查询股票数据和分析股票的日K图。
戳我去github仓库🔗